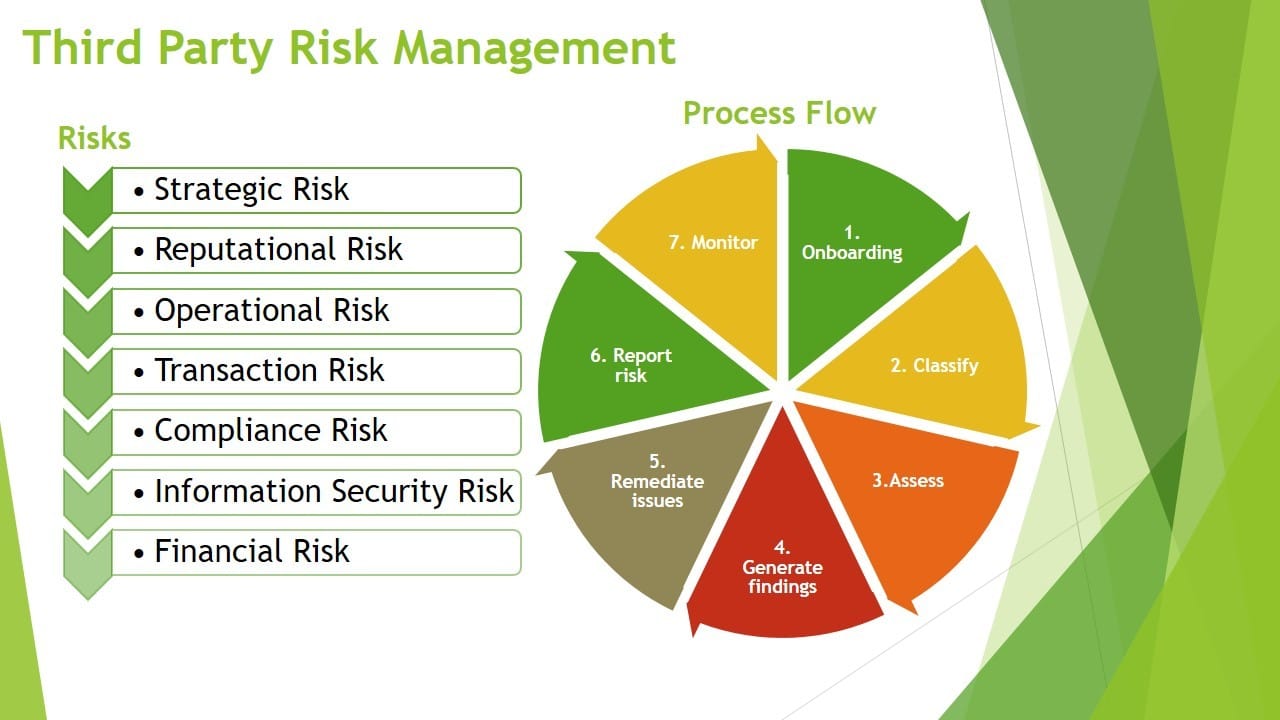
Risk Management and Business Impact Analysis (BIA) are both crucial steps in forming an Information Security Program. Which One Comes First Can Be A Point Of Debate.
Risk Management vs. Business Impact Analysis: Which Comes First in Information Security Programs?
In the ever-evolving landscape of information security, organizations face a multitude of threats and vulnerabilities. To effectively safeguard their assets, they must establish robust information security programs that encompass various strategies and methodologies. Among these, risk management and business impact analysis (BIA) are two critical components.
However, the question of which should come first often sparks debate among professionals in the field.
Understanding Risk Management and BIA
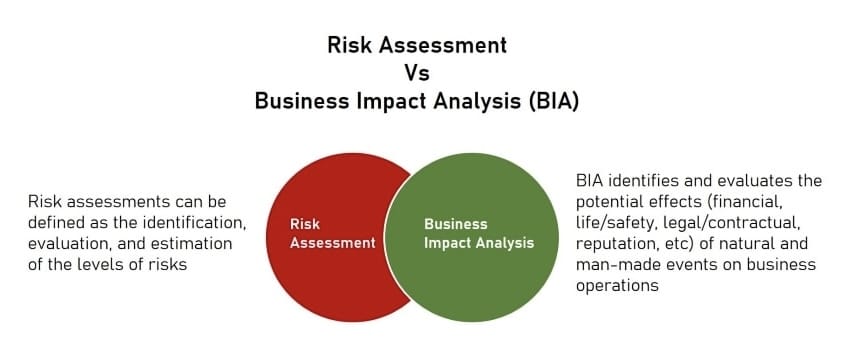
Risk Management
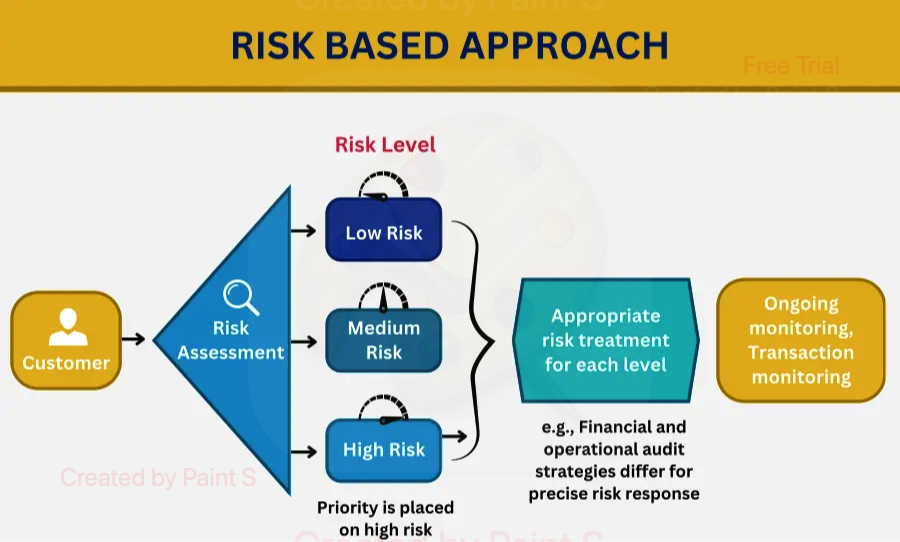
Risk management involves identifying, assessing, and prioritizing risks to minimize the impact of unforeseen events on an organization. This process is fundamental for establishing a secure environment, as it allows organizations to anticipate potential threats, allocate resources efficiently, and implement controls to mitigate identified risks.
Key components of risk management include:
- Risk Identification: Determining what risks could affect the organization.
- Risk Assessment: Evaluating the likelihood and potential impact of identified risks.
- Risk Mitigation: Developing strategies to reduce or eliminate risks.
Business Impact Analysis (BIA)
BIA, on the other hand, focuses on understanding the potential effects of business disruptions. It assesses how critical various business functions are to the organization and the consequences of those functions being interrupted. By identifying essential operations and their dependencies, BIA helps organizations prioritize recovery efforts and resources.
Key components of BIA include:
- Identifying Critical Functions: Determining which business operations are vital for organizational continuity.
- Assessing Impact: Evaluating the consequences of disruptions on these critical functions.
- Developing Recovery Strategies: Creating plans to restore essential operations in the event of a disruption.
The Debate: Which Comes First?
The debate over whether risk management or BIA should come first is rooted in the different objectives and methodologies of each process.
Advocates for Risk Management First
Proponents of starting with risk management argue that understanding risks is essential before delving into business impacts. They believe that risk management lays the groundwork for effective BIA by identifying the threats and vulnerabilities that could affect critical business functions. Without a clear understanding of risks, conducting a BIA might not yield relevant insights, as it may not account for all potential threats that could disrupt operations.
Advocates for BIA First
Conversely, those who advocate for conducting BIA first contend that understanding the potential impact of disruptions is crucial for prioritizing risks. They argue that without knowing which functions are most critical to the organization, risk assessments may lack focus and relevance. Starting with BIA allows organizations to align their risk management efforts with their most vital operations, ensuring that resources are directed toward protecting what matters most.
Here’s a perspective that draws from established standards and frameworks, such as the NIST Cybersecurity Framework and ISO 27001, to shed light on this topic.
Perspective on Order: Risk Management First

In my view, risk management should come before business impact analysis (BIA) for several reasons:
- Foundation for Informed Decision-Making:
- Risk management involves identifying, assessing, and prioritizing risks to organizational assets, including information systems. By understanding the various risks that could affect the organization, decision-makers can better determine which assets are most critical to protect.
- A comprehensive risk assessment helps to pinpoint vulnerabilities, threats, and potential impacts, which sets the stage for a more effective BIA.
- Contextualizing the BIA:
- The BIA’s primary goal is to assess the potential impacts of disruptions on business operations. Having a thorough understanding of the risks enables the BIA to focus on the most relevant scenarios and prioritize business functions that could be most affected by these risks.
- When BIA is performed with a risk-informed approach, it becomes more aligned with actual threats and vulnerabilities that the organization faces, leading to more realistic planning and resource allocation.
- Alignment with Standards:
- Frameworks like NIST SP 800-30 (Guide for Conducting Risk Assessments) and ISO 27005 (Information Security Risk Management) emphasize the need for risk assessments as a precursor to business continuity planning, which includes BIA.
- The NIST Cybersecurity Framework encourages organizations to identify and assess risks before developing their response strategies, further highlighting the importance of risk management in establishing an effective security posture.
Some authoritative sources and frameworks that support the perspective that risk management should come before business impact analysis (BIA)

In forming an information security program:
- NIST Cybersecurity Framework (NIST CSF):
- This framework emphasizes the importance of identifying risks as the first step in developing a comprehensive cybersecurity program. It guides organizations to understand their risks to inform their overall strategy.
- Source: NIST Cybersecurity Framework
- NIST SP 800-30: Guide for Conducting Risk Assessments:
- This publication outlines the process of risk assessment, which includes identifying and assessing risks to inform subsequent security decisions and planning, including BIA.
- Source: NIST SP 800-30
- ISO/IEC 27001: Information Security Management Systems (ISMS):
- This international standard provides a systematic approach to managing sensitive company information, including risk assessment as a foundational component for establishing security controls and business continuity plans, which include BIA.
- Source: ISO/IEC 27001
- ISO 22301: Societal Security – Business Continuity Management Systems:
- This standard provides requirements for a business continuity management system (BCMS) and emphasizes the need for risk assessments to inform the BIA process.
- Source: ISO 22301
- COBIT 2019: A Business Framework for the Governance and Management of Enterprise IT:
- COBIT emphasizes governance and management practices that include risk management as a critical process to ensure alignment with organizational objectives, which informs BIA and other security-related decisions.
- Source: COBIT 2019
- Business Continuity Institute (BCI) Good Practice Guidelines:
- The BCI provides guidance on best practices for business continuity management, highlighting the need for risk assessment before conducting a BIA.
- Source: BCI Good Practice Guidelines
Conclusion
Both risk management and business impact analysis are crucial steps in forming a robust information security program. The question of which should come first remains a point of debate, highlighting the complexity of managing risks and impacts within an organization. Engaging in this discussion can provide valuable insights that help organizations effectively integrate these processes to enhance their overall security posture.
Further References
Business Impact Assessment vs. Risk AssessmentCentraleyeshttps://www.centraleyes.com
Risk Assessment or Business Impact AnalysisGMH Continuity Architectshttp://www.gmhasia.com
Business Impact Analysis (BIA): A Practical ApproachIT Governance EUhttps://www.itgovernance.eu
Using Business Impact Analysis to Inform Risk Prioritization …National Institute of Standards and Technology (.gov)https://nvlpubs.nist.gov