Information security programs are not easy or totally successful on a global scale. In fact, performing a takedown—that is, successfully removing or blocking malware implemented on a vast scale and/or stopping malicious individuals or organizations that create and disseminate it—is very difficult for many reasons. Examining several cybersecurity response programs, evaluating their levels of success and describing various common malware programs can help reveal methods to help combat cyber-incidents.
Based on the information from the article “Cybersecurity Takedowns,” here are some additional, new, recommendations that align with the latest frameworks, standards, and guidelines for improving cybersecurity measures:
Enhanced Coordination and Collaboration:
Foster stronger coordination among software vendors, internet service providers, and internet malware researchers to stop malicious activities before they escalate.
Establish and support focused groups dedicated to consistent software solutions and updates across vendors.
Timely Updates and Patch Management:
Ensure timely updates of antivirus software and regular patch management to mitigate zero-day vulnerabilities.
Encourage organizations to adopt automated patch management systems to ensure consistency and timeliness.
Improved Threat Detection and Response:
Utilize AI and machine learning technologies to enhance the detection of cyber anomalies and respond to threats more effectively.
Implement robust intrusion detection and prevention systems that can quickly identify and mitigate zero-day and AI-driven attacks.
Regular Penetration Testing:
Conduct frequent penetration testing to assess the strength of cyber defenses and identify vulnerabilities before they can be exploited.
Use results from penetration tests to prioritize and remediate critical vulnerabilities.
Comprehensive Cyberhygiene Practices:
Promote good cyberhygiene practices across all organizations, regardless of size, to ensure data protection and security.
Implement secure configurations for all devices, maintain mobile device management policies, and ensure the use of approved software and applications only.
Network and Device Security Enhancements:
Protect the network by implementing segmentation, user-access controls, multifactor authentication, and continuous network monitoring.
Secure all devices through standardized configurations, regular maintenance, and real-time scanning for sensitive data movements.
Data Protection Measures:
Use data encryption for data at rest and in transit to safeguard sensitive information.
Regularly back up data and test restoration processes to ensure data integrity and availability in case of a breach or ransomware attack.
Supply Chain Security:
Conduct security reviews and assessments of supply chain partners to ensure uniform security standards.
Implement random inspections and tests to verify compliance with access and authentication controls.
Strengthening Legal and Enforcement Measures:
Advocate for stronger penalties and standardized laws across countries to deter cybercriminal activities.
Improve international cooperation for cybercrime investigations and takedowns through coordinated efforts and information sharing.
Addressing Emerging Threats:
Develop and deploy tools to recognize and mitigate threats from the Internet of Things (IoT) devices, which are often poorly secured.
Prepare for weaponized artificial intelligence threats by investing in advanced detection and mitigation technologies.
By implementing these recommendations, organizations can strengthen their cybersecurity posture and be better prepared to respond to the ever-evolving landscape of cyber threats.
Understanding the CrowdStrike IT Outage: Insights from a Former Windows Developer
Introduction
Hey, I’m Dave. Welcome to my shop.
I’m Dave Plummer, a retired software engineer from Microsoft, going back to the MS-DOS and Windows 95 days. Thanks to my time as a Windows developer, today I’m going to explain what the CrowdStrike issue actually is, the key difference in kernel mode, and why these machines are bluescreening, as well as how to fix it if you come across one.
Now, I’ve got a lot of experience waking up to bluescreens and having them set the tempo of my day, but this Friday was a little different. However, first off, I’m retired now, so I don’t debug a lot of daily blue screens. And second, I was traveling in New York City, which left me temporarily stranded as the airlines sorted out the digital carnage.
But that downtime gave me plenty of time to pull out the old MacBook and figure out what was happening to all the Windows machines around the world. As far as we know, the CrowdStrike bluescreens that we have been seeing around the world for the last several days are the result of a bad update to the CrowdStrike software. But why? Today I want to help you understand three key things.
Key Points
Why the CrowdStrike software is on the machines at all.
What happens when a kernel driver like CrowdStrike fails.
Precisely why the CrowdStrike code faults and brings the machines down, and how and why this update caused so much havoc.
Handling Crashes at Microsoft
As systems developers at Microsoft in the 1990s, handling crashes like this was part of our normal bread and butter. Every dev at Microsoft, at least in my area, had two machines. For example, when I started in Windows NT, I had a Gateway 486 DX 250 as my main dev machine, and then some old 386 box as the debug machine. Normally you would run your test or debug bits on the debug machine while connected to it as the debugger from your good machine.
Anti-Stress Process
On nights and weekends, however, we did something far more interesting. We ran a process called Anti-Stress. Anti-Stress was a bundle of tests that would automatically download to the test machines and run under the debugger. So every night, every test machine, along with all the machines in the various labs around campus, would run Anti-Stress and put it through the gauntlet.
The stress tests were normally written by our test engineers, who were software developers specially employed back in those days to find and catch bugs in the system. For example, they might write a test to simply allocate and use as many GDI brush handles as possible. If doing so causes the drawing subsystem to become unstable or causes some other program to crash, then it would be caught and stopped in the debugger immediately.
The following day, all of the crashes and assertions would be tabulated and assigned to an individual developer based on the area of code in which the problem occurred. As the developer responsible, you would then use something like Telnet to connect to the target machine, debug it, and sort it out.
Debugging in Assembly Language
All this debugging was done in assembly language, whether it was Alpha, MIPS, PowerPC, or x86, and with minimal symbol table information. So it’s not like we had Visual Studio connected. Still, it was enough information to sort out most crashes, find the code responsible, and either fix it or at least enter a bug to track it in our database.
Kernel Mode versus User Mode
The hardest issues to sort out were the ones that took place deep inside the operating system kernel, which executes at ring zero on the CPU. The operating system uses a ring system to bifurcate code into two distinct modes: kernel mode for the operating system itself and user mode, where your applications run. Kernel mode does tasks such as talking to the hardware and the devices, managing memory, scheduling threads, and all of the really core functionality that the operating system provides.
Application code never runs in kernel mode, and kernel code never runs in user mode. Kernel mode is more privileged, meaning it can see the entire system memory map and what’s in memory at any physical page. User mode only sees the memory map pages that the kernel wants you to see. So if you’re getting the sense that the kernel is very much in control, that’s an accurate picture.
Even if your application needs a service provided by the kernel, it won’t be allowed to just run down inside the kernel and execute it. Instead, your user thread will reach the kernel boundary and then raise an exception and wait. A kernel thread on the kernel side then looks at the specified arguments, fully validates everything, and then runs the required kernel code. When it’s done, the kernel thread returns the results to the user thread and lets it continue on its merry way.
Why Kernel Crashes Are Critical
There is one other substantive difference between kernel mode and user mode. When application code crashes, the application crashes. When kernel mode crashes, the system crashes. It crashes because it has to. Imagine a case where you had a really simple bug in the kernel that freed memory twice. When the kernel code detects that it’s about to free already freed memory, it can detect that this is a critical failure, and when it does, it blue screens the system, because the alternatives could be worse.
Consider a scenario where this double freed code is allowed to continue, maybe with an error message, maybe even allowing you to save your work. The problem is that things are so corrupted at this point that saving your work could do more damage, erasing or corrupting the file beyond repair. Worse, since it’s the kernel system that’s experiencing the issue, application programs are not protected from one another in the same way. The last thing you want is solitaire triggering a kernel bug that damages your git enlistment.
And that’s why when an unexpected condition occurs in the kernel, the system is just halted. This is not a Windows thing by any stretch. It is true for all modern operating systems like Linux and macOS as well. In fact, the biggest difference is the color of the screen when the system goes down. On Windows, it’s blue, but on Linux it’s black, and on macOS, it’s usually pink. But as on all systems, a kernel issue is a reboot at a minimum.
What Runs in Kernel Mode
Now that we know a bit about kernel mode versus user mode, let’s talk about what specifically runs in kernel mode. And the answer is very, very little. The only things that go in the kernel mode are things that have to, like the thread scheduler and the heap manager and functionality that must access the hardware, such as the device driver that talks to a GPU across the PCIe bus. And so the totality of what you run in kernel mode really comes down to the operating system itself and device drivers.
And that’s where CrowdStrike enters the picture with their Falcon sensor. Falcon is a security product, and while it’s not just simply an antivirus, it’s not that far off the mark to look at it as though it’s really anti-malware for the server. But rather than just looking for file definitions, it analyzes a wide range of application behavior so that it can try to proactively detect new attacks before they’re categorized and listed in a formal definition.
CrowdStrike Falcon Sensor
To be able to see that application behavior from a clear vantage point, that code needed to be down in the kernel. Without getting too far into the weeds of what CrowdStrike Falcon actually does, suffice it to say that it has to be in the kernel to do it. And so CrowdStrike wrote a device driver, even though there’s no hardware device that it’s really talking to. But by writing their code as a device driver, it lives down with the kernel in ring zero and has complete and unfettered access to the system, data structures, and the services that they believe it needs to do its job.
Everybody at Microsoft and probably at CrowdStrike is aware of the stakes when you run code in kernel mode, and that’s why Microsoft offers the WHQL certification, which stands for Windows Hardware Quality Labs. Drivers labeled as WHQL certified have been thoroughly tested by the vendor and then have passed the Windows Hardware Lab Kit testing on various platforms and configurations and are signed digitally by Microsoft as being compatible with the Windows operating system. By the time a driver makes it through the WHQL lab tests and certifications, you can be reasonably assured that the driver is robust and trustworthy. And when it’s determined to be so, Microsoft issues that digital certificate for that driver. As long as the driver itself never changes, the certificate remains valid.
CrowdStrike’s Agile Approach
But what if you’re CrowdStrike and you’re agile, ambitious, and aggressive, and you want to ensure that your customers get the latest protection as soon as new threats emerge? Every time something new pops up on the radar, you could make a new driver and put it through the Hardware Quality Labs, get it certified, signed, and release the updated driver. And for things like video cards, that’s a fine process. I don’t actually know what the WHQL turnaround time is like, whether that’s measured in days or weeks, but it’s not instant, and so you’d have a time window where a zero-day attack could propagate and spread simply because of the delay in getting an updated CrowdStrike driver built and signed.
Dynamic Definition Files
What CrowdStrike opted to do instead was to include definition files that are processed by the driver but not actually included with it. So when the CrowdStrike driver wakes up, it enumerates a folder on the machine looking for these dynamic definition files, and it does whatever it is that it needs to do with them. But you can already perhaps see the problem. Let’s speculate for a moment that the CrowdStrike dynamic definition files are not merely malware definitions but complete programs in their own right, written in a p-code that the driver can then execute.
In a very real sense, then the driver could take the update and actually execute the p-code within it in kernel mode, even though that update itself has never been signed. The driver becomes the engine that runs the code, and since the driver hasn’t changed, the cert is still valid for the driver. But the update changes the way the driver operates by virtue of the p-code that’s contained in the definitions, and what you’ve got then is unsigned code of unknown provenance running in full kernel mode.
All it would take is a single little bug like a null pointer reference, and the entire temple would be torn down around us. Put more simply, while we don’t yet know the precise cause of the bug, executing untrusted p-code in the kernel is risky business at best and could be asking for trouble.
Post-Mortem Debugging
We can get a better sense of what went wrong by doing a little post-mortem debugging of our own. First, we need to access a crash dump report, the kind you’re used to getting in the good old NT days but are now hidden behind the happy face blue screen. Depending on how your system is configured, though, you can still get the crash dump info. And so there was no real shortage of dumps around to look at. Here’s an example from Twitter, so let’s take a look. About a third of the way down, you can see the offending instruction that caused the crash.
It’s an attempt to move data to register nine by loading it from a memory pointer in register eight. Couldn’t be simpler. The only problem is that the pointer in register eight is garbage. It’s not a memory address at all but a small integer of nine c hex, which is likely the offset of the field that they’re actually interested in within the data structure. But they almost certainly started with a null pointer, then added nine c to it, and then just dereferenced it.
CrowdStrike driver woes
Now, debugging something like this is often an incremental process where you wind up establishing, “Okay, so this bad thing happened, but what happened upstream beforehand to cause the bad thing?” And in this case, it appears that the cause is the dynamic data file downloaded as a sys file. Instead of containing p-code or a malware definition or whatever was supposed to be in the file, it was all just zeros.
We don’t know yet how or why this happened, as CrowdStrike hasn’t publicly released that information yet. What we do know to an almost certainty at this point, however, is that the CrowdStrike driver that processes and handles these updates is not very resilient and appears to have inadequate error checking and parameter validation.
Parameter validation means checking to ensure that the data and arguments being passed to a function, and in particular to a kernel function, are valid and good. If they’re not, it should fail the function call, not cause the entire system to crash. But in the CrowdStrike case, they’ve got a bug they don’t protect against, and because their code lives in ring zero with the kernel, a bug in CrowdStrike will necessarily bug check the entire machine and deposit you into the very dreaded recovery bluescreen.
Windows Resilience
Even though this isn’t a Windows issue or a fault with Windows itself, many people have asked me why Windows itself isn’t just more resilient to this type of issue. For example, if a driver fails during boot, why not try to boot next time without it and see if that helps?
And Windows, in fact, does offer a number of facilities like that, going back as far as booting NT with the last known good registry hive. But there’s a catch, and that catch is that CrowdStrike marked their driver as what’s known as a bootstart driver. A bootstart driver is a device driver that must be installed to start the Windows operating system.
Most bootstart drivers are included in driver packages that are in the box with Windows, and Windows automatically installs these bootstart drivers during their first boot of the system. My guess is that CrowdStrike decided they didn’t want you booting at all without their protection provided by their system, but when it crashes, as it does now, your system is completely borked.
Fixing the Issue
Fixing a machine with this issue is fortunately not a great deal of work, but it does require physical access to the machine. To fix a machine that’s crashed due to this issue, you need to boot it into safe mode, because safe mode only loads a limited set of drivers and mercifully can still contend without this boot driver.
You’ll still be able to get into at least a limited system. Then, to fix the machine, use the console or the file manager and go to the path window like windows, and then system32/drivers/crowdstrike. In that folder, find the file matching the pattern c and then a bunch of zeros 291 sys and delete that file or anything that’s got the 291 in it with a bunch of zeros. When you reboot, your system should come up completely normal and operational.
The absence of the update file fixes the issue and does not cause any additional ones. It’s a fair bet that the update 291 won’t ever be needed or used again, so you’re fine to nuke it.
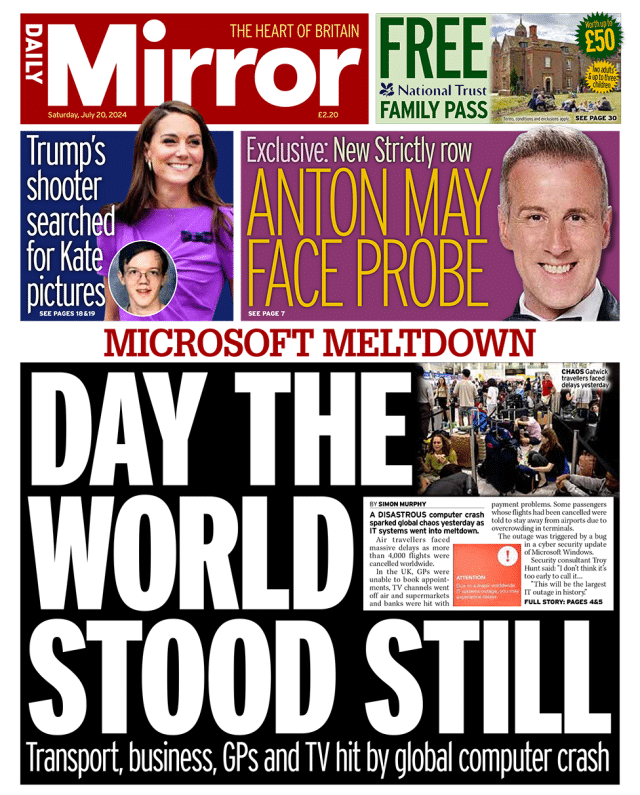
The Great Digital Blackout: Fallout from the CrowdStrike-Microsoft Outage
i. Introduction
On a seemingly ordinary Friday morning, the digital world shuddered. A global IT outage, unprecedented in its scale, brought businesses, governments, and individuals to a standstill. The culprit: a faulty update from cybersecurity firm CrowdStrike, clashing with Microsoft Windows systems. The aftershocks of this event, dubbed the “Great Digital Blackout,” continue to reverberate, raising critical questions about our dependence on a handful of tech giants and the future of cybersecurity.
ii. The Incident
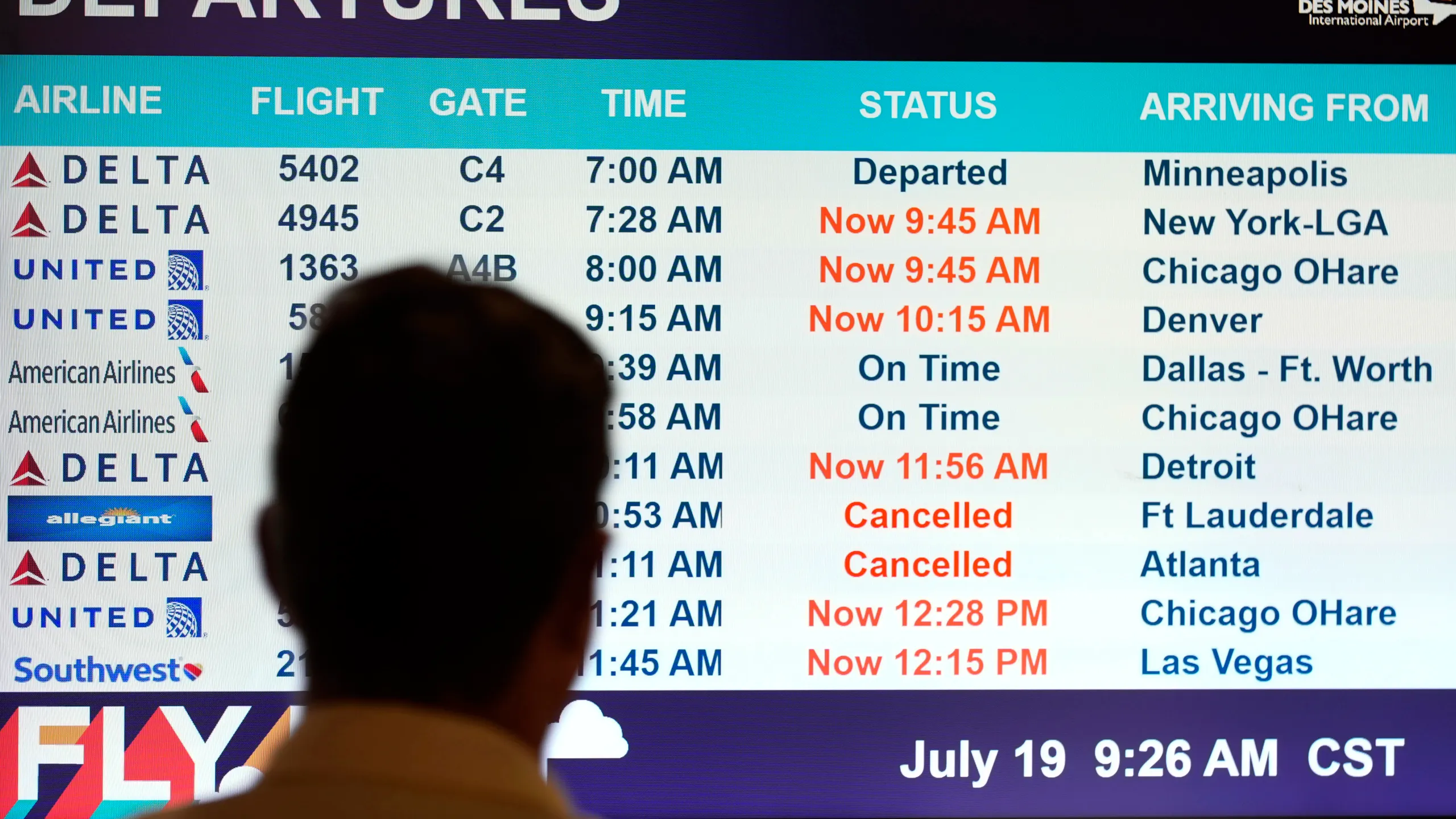
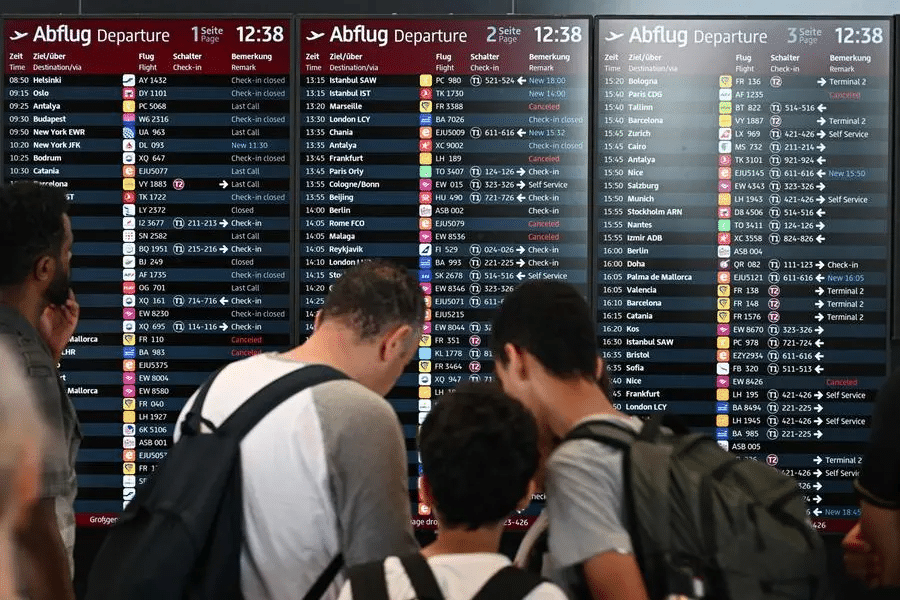
A routine software update within Microsoft’s Azure cloud platform inadvertently triggered a cascading failure across multiple regions. This outage, compounded by a simultaneous breach of CrowdStrike’s security monitoring systems, created a perfect storm of disruption. Within minutes, critical services were rendered inoperative, affecting millions of users and thousands of businesses worldwide. The outage persisted for 48 hours, making it one of the longest and most impactful in history.
iii. Initial Reports and Response
The first signs that something was amiss surfaced around 3:00 AM UTC when users began reporting issues accessing Microsoft Azure and Office 365 services. Concurrently, Crowdstrike’s Falcon platform started exhibiting anomalies. By 6:00 AM UTC, both companies acknowledged the outage, attributing the cause to a convergence of system failures and a sophisticated cyber attack exploiting vulnerabilities in their systems.
Crowdstrike and Microsoft activated their incident response protocols, working around the clock to mitigate the damage. Microsoft’s global network operations team mobilized to isolate affected servers and reroute traffic, while Crowdstrike’s cybersecurity experts focused on containing the breach and analyzing the attack vectors.
iv. A Perfect Storm: Unpacking the Cause
A. The outage stemmed from a seemingly innocuous update deployed by CrowdStrike, a leading provider of endpoint security solutions. The update, intended to bolster defenses against cyber threats, triggered a series of unforeseen consequences. It interfered with core Windows functionalities, causing machines to enter a reboot loop, effectively rendering them unusable.
B. The domino effect was swift and devastating. Businesses across various sectors – airlines, hospitals, banks, logistics – found themselves crippled. Flights were grounded, financial transactions stalled, and healthcare operations were disrupted.
C. The blame game quickly ensued. CrowdStrike, initially silent, eventually acknowledged their role in the outage and apologized for the inconvenience. However, fingers were also pointed at Microsoft for potential vulnerabilities in their Windows systems that allowed the update to wreak such havoc.
v. Immediate Consequences (Businesses at a Standstill)
The immediate impact of the outage was felt by businesses worldwide.
A. Microsoft: Thousands of companies dependent on Microsoft’s Azure cloud services found their operations grinding to a halt. E-commerce platforms experienced massive downtimes, losing revenue by the minute. Hospital systems relying on cloud-based records faced critical disruptions, compromising patient care.
Businesses dependent on Azure’s cloud services for their operations found themselves paralyzed. Websites went offline, financial transactions were halted, and communication channels were disrupted.
B. Crowdstrike: Similarly, Crowdstrike’s clientele, comprising numerous Fortune 500 companies, grappled with the fallout. Their critical security monitoring and threat response capabilities were significantly hindered, leaving them vulnerable.
vi. Counting the Costs: Beyond Downtime
The human and economic toll of the Great Digital Blackout is still being calculated. While initial estimates suggest billions of dollars in lost productivity, preliminary estimates suggest that the outage resulted in global economic losses exceeding $200 billion, the true cost extends far beyond financial figures. Businesses across sectors reported significant revenue losses, with SMEs particularly hard-hit. Recovery and mitigation efforts further strained financial resources, and insurance claims surged as businesses sought to recoup their losses.
Erosion of Trust: The incident exposed the fragility of our increasingly digital world, eroding trust in both CrowdStrike and Microsoft. Businesses and organizations now question the reliability of security solutions and software updates.
Supply Chain Disruptions: The interconnectedness of global supply chains was thrown into disarray.Manufacturing, shipping, and logistics faced delays due to communication breakdowns and the inability to process orders electronically.
Cybersecurity Concerns: The outage highlighted the potential for cascading effects in cyberattacks. A seemingly minor breach in one system can have a devastating ripple effect across the entire digital ecosystem.
vii. Reputational Damage
Both Microsoft and CrowdStrike suffered severe reputational damage. Trust in Microsoft’s Azure platform and CrowdStrike’s cybersecurity solutions was shaken. Customers, wary of future disruptions, began exploring alternative providers and solutions. The incident underscored the risks of over-reliance on major service providers and ignited discussions about diversifying IT infrastructure.
viii. Regulatory Scrutiny
In the wake of the outage, governments and regulatory bodies worldwide called for increased oversight and stricter regulations. The incident highlighted the need for robust standards to ensure redundancy, effective backup systems, and rapid recovery protocols. In the United States, discussions about enhancing the Cybersecurity Maturity Model Certification (CMMC) framework gained traction, while the European Union considered expanding the scope of the General Data Protection Regulation (GDPR) to include mandatory resilience standards for IT providers.
ix. Data Security and Privacy Concerns
One of the most concerning aspects of the outage was the potential exposure of sensitive data. Both Microsoft and Crowdstrike store vast amounts of critical and confidential data. Although initial investigations suggested that the attackers did not exfiltrate data, the sheer possibility raised alarms among clients and regulatory bodies worldwide.
Governments and compliance agencies intensified their scrutiny, reinforcing the need for robust data protection measures. Customers demanded transparency about what data, if any, had been compromised, leading to an erosion of trust in cloud services.
x. Root Causes and Analysis
Following the containment of the outage, both Crowdstrike and Microsoft launched extensive investigations to determine the root causes. Preliminary reports cited a combination of factors:
A. Zero-Day Exploits: The attackers leveraged zero-day vulnerabilities in both companies’ systems, which had not been previously detected or patched.
B. Supply Chain Attack: A key supplier providing backend services to both companies was compromised, allowing the attackers to penetrate deeper into their networks.
C. Human Error: Configuration errors and lack of stringent security checks at critical points amplified the impact of the vulnerabilities.
D. Coordinated Attack: Cybersecurity analysts suggested that the attack bore the hallmarks of a highly coordinated and well-funded group, potentially a nation-state actor, given the sophistication and scale. The alignment of the outage across multiple critical services pointed to a deliberate and strategic attempt to undermine global technological infrastructure.
xi. Response Strategies
A. CrowdStrike’s Tactics
Swift Containment: Immediate action was taken to contain the breach. CrowdStrike’s incident response teams quickly identified and isolated the compromised segments of their network to prevent further penetration.
Vulnerability Mitigation: Patches were rapidly developed and deployed to close the exploited security gaps. Continuous monitoring for signs of lingering threats or additional vulnerabilities was intensified.
Client Communication: Transparency became key. CrowdStrike maintained open lines of communication with its clients, providing regular updates, guidance on protective measures, and reassurance to mitigate the trust deficit.
B. Microsoft’s Actions
Global Response Scaling: Leveraging its extensive resources, Microsoft scaled up its global cybersecurity operations. Frantic efforts were made to stabilize systems, restore services, and strengthen defenses against potential residual threats.
Service Restoration: Microsoft prioritized the phased restoration of services. This approach ensured that each phase underwent rigorous security checks to avoid reintroducing vulnerabilities.
Collaboration and Information Sharing: Recognizing the widespread impact, Microsoft facilitated collaboration with other tech firms, cybersecurity experts, and government agencies. Shared intelligence helped in comprehending the attack’s full scope and in developing comprehensive defense mechanisms.
xii. Broad Implications
A. Evolving Cyber Threat Landscape
Increased Sophistication: The attack underscored the evolving sophistication of cyber threats. Traditional security measures are proving insufficient against highly organized and well-funded adversaries.
Proactive Security Posture: The event emphasized the need for a proactive security stance, which includes real-time threat intelligence, continuous system monitoring, and regular vulnerability assessments.
B. Trust in Cloud Computing
Cloud Strategy Reevaluation: The reliance on cloud services came under scrutiny. Organizations began rethinking their cloud strategies, weighing the advantages against the imperative of reinforcing security protocols.
Strengthened Security Measures: There is a growing emphasis on bolstering supply chain security. Companies are urged to implement stringent controls, cross-verify practices with their vendors, and engage in regular security audits.
xiii. A Catalyst for Change: Lessons Learned
The Great Digital Blackout serves as a stark reminder of the need for a comprehensive reevaluation of our approach to cybersecurity and technology dependence. Here are some key takeaways:
Prioritize Security by Design: Software development and security solutions need to prioritize “security by design” principles. Rigorous testing and vulnerability assessments are crucial before deploying updates.
Enhanced Cybersecurity: The breach of CrowdStrike’s systems highlighted potential vulnerabilities in cybersecurity frameworks. Enhanced security measures and continuous monitoring are vital to prevent similar incidents.
Diversity and Redundancy: Over-reliance on a few tech giants can be a vulnerability. Diversifying software and service providers, coupled with built-in redundancies in critical systems, can mitigate the impact of such outages.
Redundancy and Backup: The incident underscored the necessity of having redundant systems and robust backup solutions. Businesses are now more aware of the importance of investing in these areas to ensure operational continuity during IT failures.
Disaster Recovery Planning: Effective disaster recovery plans are critical. Regular drills and updates to these plans can help organizations respond more efficiently to disruptions.
Communication and Transparency: Swift, clear communication during disruptions is essential. Both CrowdStrike and Microsoft initially fell short in this area, causing confusion and exacerbating anxieties.
Regulatory Compliance: Adhering to evolving regulatory standards and being proactive in compliance efforts can help businesses avoid penalties and build resilience.
International Collaboration: Cybersecurity threats require an international response. Collaboration between governments, tech companies, and security experts is needed to develop robust defense strategies and communication protocols.
xiv. The Road to Recovery: Building Resilience
The path towards recovery from the Great Digital Blackout is multifaceted. It involves:
Post-Mortem Analysis: Thorough investigations by CrowdStrike, Microsoft, and independent bodies are needed to identify the root cause of the outage and prevent similar occurrences.
Investing in Cybersecurity Awareness: Educating businesses and individuals about cyber threats and best practices is paramount. Regular training and simulation exercises can help organizations respond more effectively to future incidents.
Focus on Open Standards: Promoting open standards for software and security solutions can foster interoperability and potentially limit the impact of individual vendor issues.
xv. A New Era of Cybersecurity: Rethinking Reliance
The Great Digital Blackout serves as a wake-up call. It underscores the need for a more robust, collaborative, and adaptable approach to cybersecurity. By diversifying our tech infrastructure, prioritizing communication during disruptions, and fostering international cooperation, we can build a more resilient digital world.
The event also prompts a conversation about our dependence on a handful of tech giants. While these companies have revolutionized our lives, the outage highlighted the potential pitfalls of such concentrated power.
xvi. Conclusion
The future of technology may involve a shift towards a more decentralized model, with greater emphasis on data sovereignty and user control. While the full impact of the Great Digital Blackout is yet to be fully understood, one thing is certain – the event has irrevocably altered the landscape of cybersecurity, prompting a global conversation about how we navigate the digital age with greater awareness and resilience.
This incident serves as a stark reminder of the interconnected nature of our digital world. As technology continues to evolve, so too must our approaches to managing the risks it brings. The lessons learned from this outage will undoubtedly shape the future of IT infrastructure, making it more robust, secure, and capable of supporting the ever-growing demands of the digital age.
Cybersecurity and Business Continuity: A United Front
In an increasingly digitized world, the convergence of cybersecurity and business continuity has become imperative for organizations striving to thrive amidst evolving threats and disruptions.
As businesses rely more on interconnected systems and data, the lines between cybersecurity and business continuity blur, necessitating a unified approach to safeguarding assets, maintaining operations, and ensuring resilience.
From the vantage point of a security leader, it’s clear that proactive measures and strategic integration are essential for organizational success.
i. Understanding the Convergence
The convergence of cybersecurity and business continuity is fundamentally about embedding cybersecurity considerations into the planning, implementation, and execution of business continuity strategies. Cybersecurity incidents can disrupt business operations as much as traditional physical risks, like natural disasters. Consequently, the modern security leader’s role involves harmonizing cybersecurity efforts with business continuity planning to ensure the organization can rapidly recover and maintain operations in the face of cyber incidents.
ii. Cybersecurity and business continuity (BC) are often viewed as separate entities
However, a security leader’s perspective emphasizes their convergence for organizational success.
o Shared Objectives: Both disciplines aim to safeguard an organization’s critical operations from disruptions. Cybersecurity protects against cyberattacks, while BC ensures continuity during unforeseen events.
o Collaborative Approach: Aligning these functions strengthens an organization’s resilience. Security leaders advocate for integrated planning and resource sharing to address common threats.
o Proactive Measures: Effective BC incorporates cybersecurity measures. Security leaders advise on incorporating cybersecurity risks into BC assessments and implementing safeguards like data backups and incident response plans.
o Communication and Awareness: Both cybersecurity and BC rely on employee awareness. Security leaders promote regular training and communication to ensure employees can identify and report security threats.
iii. Strategies for Thriving amid Cyber Threats
A. Comprehensive Risk Assessments: Organizations must adopt a holistic approach to risk assessments, considering both cyber threats and other operational risks. By understanding the full spectrum of potential disruptions, from IT system failures to sophisticated cyber-attacks, organizations can develop more robust and comprehensive continuity plans.
B. Integration of Cyber Response into Business Continuity Plans: Traditional business continuity plans often focus on recovering from physical damage to assets, but they must now include protocols for responding to cyber incidents. This means having a clear procedure for triaging cyber incidents, mitigating damage, and rapidly restoring affected systems to ensure business operations can continue.
C. Developing Cyber Resilience: Cyber resilience goes beyond prevention, focusing on an organization’s ability to anticipate, withstand, recover from, and adapt to adverse conditions, stresses, attacks, or compromises on systems. This involves implementing robust cybersecurity measures, such as encryption, multi-factor authentication, and regular security audits, alongside traditional business continuity measures.
D. Continuous Training and Awareness: Employees are often the first line of defense against cyber threats. Regular training and awareness campaigns on cybersecurity hygiene, phishing, and other prevalent cyber risks are essential to empower employees to act as custodians of organizational security.
E. Leveraging Technology for Disaster Recovery: Advanced technologies like cloud computing offer unprecedented opportunities for enhancing business continuity. Through the cloud, organizations can implement off-site backups, disaster recovery, and secure access to business applications, ensuring operational resilience in the face of cyber disruptions.
F. Collaboration and Communication: In the event of a cyber incident, clear and effective communication with internal and external stakeholders can mitigate panic, preserve reputation, and ensure a coordinated response. This includes having predefined communication templates and channels ready for use in the event of an incident.
G. Regular Testing and Simulation: Just as fire drills are essential for physical safety, regular cyber drills and business continuity simulations are crucial. These exercises not only test the effectiveness of plans and protocols but also prepare employees to respond effectively under stress.
H. Agile and Adaptive Planning: The cyber threat landscape is rapidly evolving; thus, business continuity plans must be dynamic. Regular reviews and updates in response to emerging threats and technological advancements ensure plans remain relevant and effective.
iv. By fostering collaboration between cybersecurity and BC teams, organizations can:
o Enhance preparedness: Aligning these functions strengthens an organization’s ability to respond to crises effectively.
o Minimize downtime: Swift recovery from disruptions ensures business continuity and minimizes financial losses.
o Build resilience: A converged approach strengthens an organization’s overall security posture and ability to adapt to evolving threats.
v. The Unified Approach
To effectively address these challenges, organizations must adopt a unified approach that integrates cybersecurity and business continuity strategies. This entails aligning objectives, coordinating efforts, and leveraging synergies between the two disciplines.
A. Risk Management Integration: By assessing cybersecurity risks alongside business continuity risks, organizations can develop a comprehensive understanding of their threat landscape and prioritize mitigation efforts accordingly. This holistic approach enables informed decision-making and resource allocation to mitigate risks effectively.
B. Incident Response Planning: Establishing integrated incident response plans enables organizations to respond swiftly and effectively to cyber incidents, business disruptions, or hybrid events that impact both domains. Coordinated communication, collaboration, and resource mobilization are critical during crisis situations to minimize impact and expedite recovery.
C. Resilience Testing and Training: Regular testing and simulation exercises, such as tabletop exercises and cyber incident simulations, help validate preparedness and identify areas for improvement across cybersecurity and business continuity functions. Additionally, ongoing training and awareness programs ensure that employees are equipped to recognize and respond to emerging threats and disruptions proactively.
D. Technology Alignment: Integrating cybersecurity solutions with business continuity technologies, such as data backup and recovery systems, enhances resilience and ensures seamless continuity of operations during cyber incidents or disasters. Furthermore, leveraging automation and AI-driven technologies can strengthen defense capabilities and augment response capabilities.
E. Regulatory Compliance and Governance: Harmonizing compliance requirements across cybersecurity and business continuity frameworks streamlines governance processes and reduces regulatory overhead. This approach facilitates compliance with industry standards, regulations, and contractual obligations while enhancing overall security posture and resilience.
vi. The Role of Security Leaders
Security leaders play a pivotal role in driving the convergence of cybersecurity and business continuity within their organizations. By fostering collaboration, promoting a culture of resilience, and advocating for integrated strategies, security leaders can empower their teams to mitigate risks effectively and safeguard organizational assets.
A. Strategic Leadership: Security leaders must champion the integration of cybersecurity and business continuity as strategic imperatives aligned with broader business objectives. By engaging with executive leadership and board members, security leaders can garner support and resources to implement unified strategies and initiatives.
B. Cross-functional Collaboration: Collaboration across departments, including IT, operations, risk management, and legal, is essential for ensuring alignment and synergy between cybersecurity and business continuity efforts. Security leaders should facilitate cross-functional teams and initiatives to address shared challenges and achieve common goals.
C. Continuous Improvement: Emphasizing a culture of continuous improvement and learning is crucial for staying ahead of evolving threats and disruptions. Security leaders should encourage feedback, foster innovation, and invest in professional development to equip their teams with the skills and knowledge needed to adapt and thrive in dynamic environments.
vii. Conclusion
In an era defined by digital transformation, organizations must recognize the symbiotic relationship between cybersecurity and business continuity and embrace a unified approach to resilience.
By integrating strategies, aligning objectives, and fostering collaboration, organizations can mitigate risks, enhance operational resilience, and thrive amidst uncertainty.
Security leaders, as catalysts for change, have a pivotal role in driving this convergence and ensuring that organizations are well-positioned to navigate the evolving threat landscape and seize opportunities for growth and success.
Elevating Customer Centricity: The Impact of ISO 22301 Business Continuity Implementation
In an era where customer expectations are higher than ever, organizations strive not only to meet but to exceed these demands to secure customer loyalty and achieve competitive advantage.
One strategic approach to accomplishing this is by adopting a customer-centric model, prioritizing customer needs and satisfaction in every decision and process.
A critical component of embedding customer centricity into the organizational culture is ensuring business continuity.
By implementing the ISO 22301 standard for business continuity management, organizations can demonstrate their dedication to their customers through resilience, reliability, and responsiveness.
i. Understanding ISO 22301
ISO 22301 is an internationally recognized standard that specifies requirements for setting up and managing an effective Business Continuity Management System (BCMS).
It provides a framework for organizations to prepare for, respond to, and recover from disruptions effectively.
Disruptions can range from natural disasters to technology failures or cyber-attacks, any of which can significantly impact an organization’s operations and, consequently, its customers.
It’s about ensuring the continuity of critical business functions, which is directly linked to serving customers’ needs and expectations.
ii. Building Customer Trust
The implementation of ISO 22301 plays a pivotal role in building and maintaining customer trust. It signals to customers that an organization is committed to maintaining operations and service levels, even in the face of unforeseen disruptions.
This assurance can be particularly crucial for retaining customer loyalty in industries where the cost of downtime is high, both for the customer and the service provider, including finance, healthcare, and telecommunications.
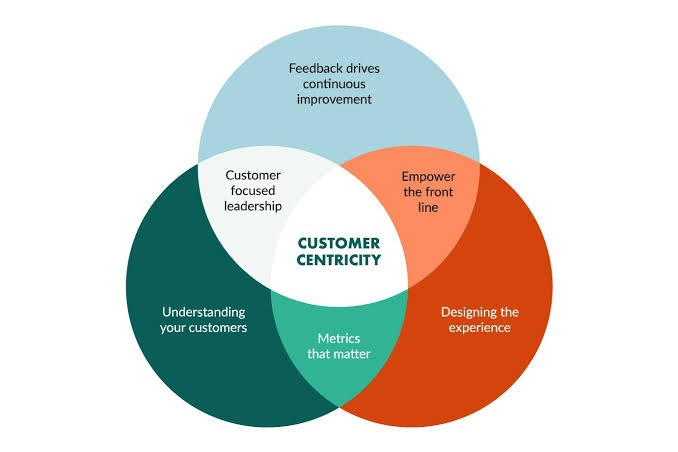
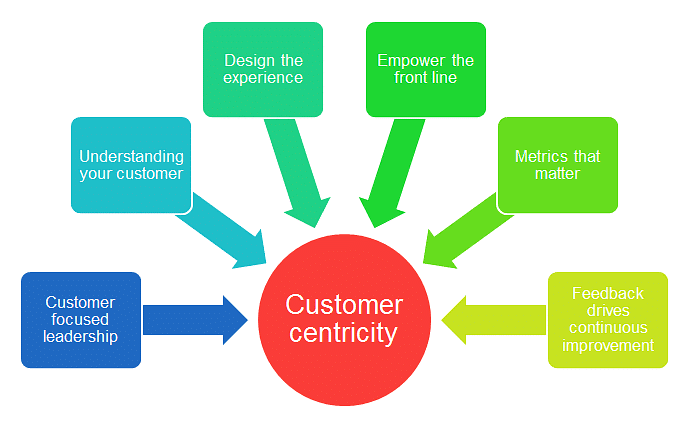
iii. The Link between Business Continuity and Customer Centricity
At its core, customer centricity involves placing the customer at the center of every decision-making process, crafting products, services, and experiences around their needs and preferences.
Implementing business continuity, particularly through the lens of ISO 22301, enhances customer centricity in several key ways:
A. Ensuring Reliability
Customers expect reliability and consistency from the businesses they patronize. By adopting ISO 22301, organizations can demonstrate a commitment to maintaining service standards, even in the face of operational disruptions. This reliability fosters trust and loyalty, vital components of a customer-centric business ethos.
B. Minimizing Disruptions
The methodologies outlined in ISO 22301 help businesses identify potential threats to operations and implement preventive measures to mitigate these risks. For customers, this means fewer service interruptions and a steady, dependable delivery of products and services.
C. Transparent Communication
A core principle of ISO 22301 is effective communication, both internally and externally. During disruptions, a business continuity plan ensures that customers are kept informed about the status of operations, expected recovery times, and any temporary measures put in place to maintain service delivery. This transparency is crucial in maintaining customer trust and satisfaction.
D. Adaptability to Customer Needs
The process of implementing ISO 22301 involves a deep understanding of an organization’s critical functions and their impact on customers. This knowledge enables businesses to prioritize recovery efforts based on what is most important to their customers, demonstrating an adaptable, customer-first approach.
E. Swift Recovery
A BCM plan facilitates a faster recovery after disruptions, enabling organizations to resume serving customers efficiently. This minimizes the overall impact on customer satisfaction.
F. Risk Assessment
ISO 22301 promotes ongoing risk assessment, including those that could affect customer service. By proactively addressing these risks, organizations can safeguard customer experience.
G. Competitive Advantage
In an increasingly competitive business environment, the ability to maintain operations during disruptions can be a key differentiator. Organizations that prove resilient are more likely to retain customers and attract new ones, who value the reliability and security of their service providers.
H. Enhanced Reputation
Companies that effectively implement business continuity management systems gain a reputation for reliability and responsibility. This reputation is invaluable in building and maintaining customer relationships, as trust becomes increasingly important in consumer decision-making processes.
iv. Implementing Business Continuity with a Customer-Centric Approach
To truly harness the benefits of ISO 22301 in promoting customer centricity, organizations should:
o Engage Customers in Business Continuity Planning: Understanding customer needs and expectations can help tailor business continuity strategies that align with what is most important to them.
o Focus on Communication: Develop clear, transparent communication channels to inform customers about potential disruptions and recovery efforts.
o Prioritize Critical Functions: Identify and prioritize functions that have the most significant impact on customers, ensuring these areas are robustly protected and quickly recoverable.
v. Conclusion
Implementing business continuity management according to ISO 22301 standards is not merely about resilience; it’s a strategic approach that inherently prioritizes the customer.
In today’s fast-paced and uncertain business environment, being customer-centric means being prepared.
It’s about ensuring continuity and reliability, values that lie at the heart of customer trust and loyalty.
In conclusion, the implementation of ISO 22301 enhances customer-centricity by fortifying an organization’s ability to maintain operations, communicate effectively during disruptions, protect customer data, and continually improve its resilience.
By adopting this international standard, businesses not only safeguard their own continuity but also strengthen the foundation of trust and satisfaction with their valued customers.
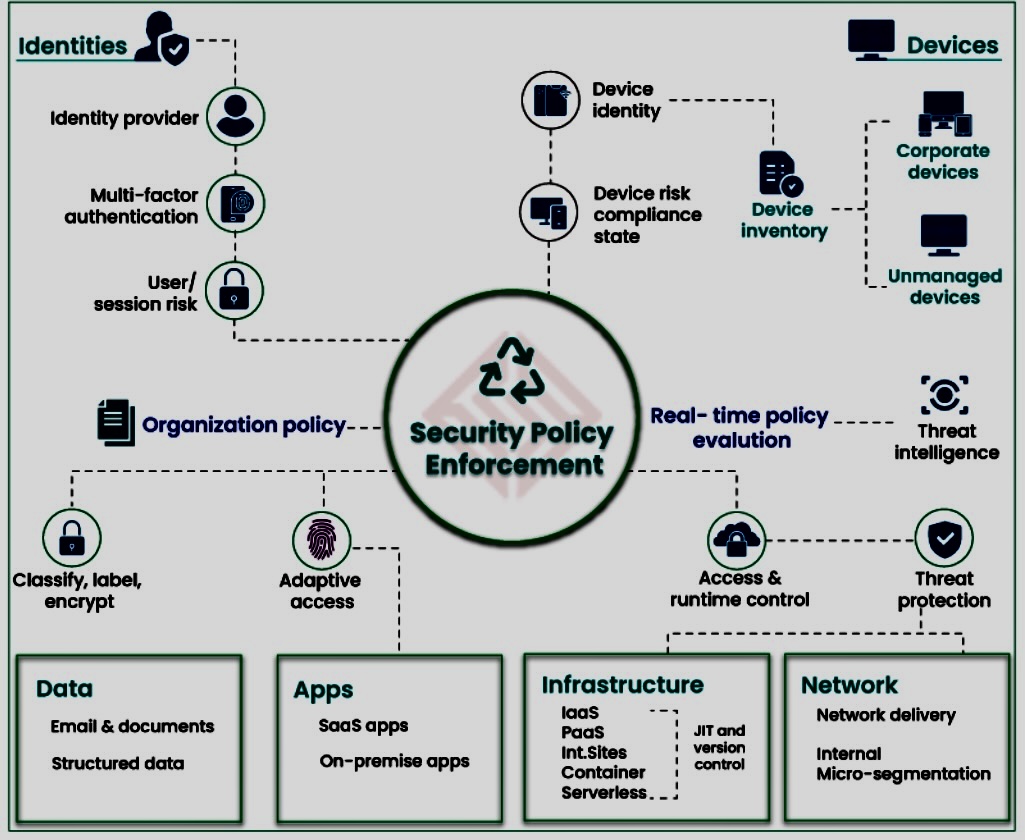
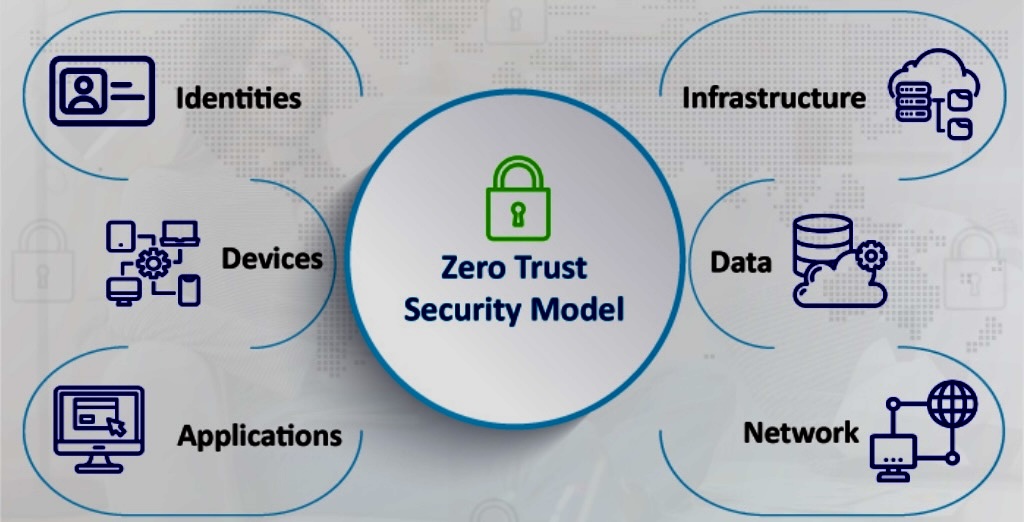
Zero Trust is a security concept centered on the belief that organizations should not automatically trust anything inside or outside its perimeters and instead must verify anything and everything trying to connect to its systems before granting access.
How Zero Trust can help in reducing the cost of security:
A. Definition of Zero Trust:
o Principle: Zero Trust is a cybersecurity framework that operates on the assumption that organizations should not automatically trust anything, inside or outside their network perimeter. Every user, device, and application is treated as untrusted, requiring continuous verification.
B. Traditional Security Challenges:
o Perimeter Reliance: Traditional security models rely heavily on perimeter defenses, assuming that once inside, entities can be trusted. This approach becomes insufficient in the face of sophisticated cyber threats.
C. Key Principles of Zero Trust:
o Verify Identity: Continuously verify the identity of users, devices, and applications.
o Least Privilege: Grant the minimum level of access required for users and systems to perform their tasks.
o Micro-Segmentation: Segment the network into small, isolated zones to contain and minimize the impact of potential breaches.
o Continuous Monitoring: Implement continuous monitoring and analysis of network activities for anomalies.
D. Reduced Risk of Data Breaches: Zero trust can help to reduce the risk of data breaches by preventing unauthorized access to sensitive data. This can save organizations millions of dollars in potential costs associated with data breaches, such as fines, legal fees, and remediation costs.
E. Reduced Attack Surface: By enforcing least-privilege access, Zero Trust minimizes the attack surface, and hence the potential for intrusions. Fewer attacks mean less money needing to be spent on threat hunting, incident response, and remediation efforts.
F. Improved Compliance: Zero trust can help organizations to comply with data privacy regulations, such as GDPR and CCPA. This can reduce the risk of fines and other penalties for non-compliance.
G. Rationalization of Tools: Implementing a Zero Trust architecture often forces organizations to rationalize the security tools they use, which can lead to cost savings by eliminating redundant or underutilized solutions.
H. Automation: Zero Trust can lead to greater levels of security automation, as consistent policies are easier to automate. Automation can subsequently lead to lower labor costs and fewer human errors.
I. Flexible Work Arrangements: Zero Trust allows employees to securely access business systems and data from any location or device, reducing the need for costly on-site IT infrastructure.
J. Proactive Approach: Instead of a reactive stance where organizations respond to incidents after they occur, Zero Trust takes a proactive approach by consistently verifying every user and every action, potentially stopping attacks before they happen.
K. Enhanced Productivity: Zero trust can help to increase employee productivity by reducing downtime caused by security incidents. This can save organizations millions of dollars in lost productivity each year.
L. Improved Reputation: Zero trust can help to improve an organization’s reputation by demonstrating its commitment to data security. This can attract new customers and partners and retain existing ones.
M. Cost Reduction through Zero Trust:
o Minimized Data Exposure: Zero Trust helps minimize data exposure by enforcing least privilege. This reduces the potential impact of a data breach and associated cleanup costs.
o Prevention of Lateral Movement: By segmenting the network and requiring continuous verification, Zero Trust limits the ability of attackers to move laterally within the network, preventing the spread of a compromise.
o Reduced Incident Response Costs: With continuous monitoring and early detection, Zero Trust facilitates quicker incident response, minimizing the financial impact of security incidents.
o Savings on Compliance Penalties: Zero Trust aids in maintaining compliance by enforcing strict access controls and data protection measures, reducing the risk of regulatory fines.
N. Implementation Steps:
o Identify and Classify Assets: Identify and classify assets, determining their criticality and sensitivity.
o Implement Least Privilege: Enforce the principle of least privilege, ensuring users and systems have only the necessary access.
o Continuous Monitoring: Invest in tools and processes for continuous monitoring of network activities, detecting anomalies promptly.
o Micro-Segmentation: Implement micro-segmentation to compartmentalize the network and limit lateral movement.
o User and Device Authentication: Strengthen user and device authentication mechanisms, including multi-factor authentication.
O. Technology Enablers:
o Zero Trust Access (ZTA): Utilize Zero Trust Access solutions that enable secure access to applications and data based on the principle of continuous verification.
o Software-Defined Perimeter (SDP): Implement SDP to dynamically create secure perimeters around specific applications or data, reducing the attack surface.
Q. Collaboration and User Education:
o Employee Training: Educate employees about the principles of Zero Trust, emphasizing their role in maintaining a secure environment.
o Collaboration with Vendors: Work collaboratively with third-party vendors and partners to extend Zero Trust principles to external entities.
R. Regular Audits and Assessments:
o Periodic Assessments: Conduct regular assessments and audits to ensure that Zero Trust policies are effectively implemented and aligned with evolving security requirements.
S. Adaptation to Evolving Threats:
o Continuous Improvement: Continuously adapt Zero Trust measures to address new and evolving cyber threats. Regularly review and update security controls.
T. Improve incident response: Zero trust can help organizations to respond to security incidents more quickly and effectively.
U. Business Continuity and Resilience:
o Enhanced Resilience: Zero Trust enhances business resilience by minimizing the impact of security incidents and enabling swift recovery.
Although there may be upfront costs associated with switching to a Zero Trust model, the long-term cost-saving benefits often outweigh these initial investments.
By prioritizing continuous verification, least privilege access, and effective segmentation, organizations can strengthen their defenses and minimize the financial and operational impact of security incidents.
Application classification can refer to a number of concepts, many of which revolve around organizing software, data, and functions based on their purpose, features, or functionality.
i. Purposes of Application Classification
A. Resource Allocation: Application classification helps organizations identify applications with similar resource requirements, enabling efficient resource allocation and planning.
B. Risk Management: Classifying applications based on their sensitivity and potential impact helps prioritize risk mitigation efforts and safeguard critical assets.
C. Cost Optimization: Identifying redundant or underutilized applications through classification can lead to cost savings and optimization of software licensing and maintenance expenses.
D. Compliance: Classifying applications based on data types, security requirements, and regulatory compliance can streamline compliance audits and ensure adherence to industry standards.
E. Application Rationalization: Application classification facilitates the identification of overlapping or outdated applications, enabling rationalization decisions to optimize the application portfolio.
ii. key aspects of application classification
A. Business Function: Classifying applications based on the business process they support, such as customer relationship management (CRM), supply chain management (SCM), or financial management.
B. Criticality to Business: Critical, Essential, Non-Essential: Classify applications based on their criticality to business operations. Critical applications are vital for core business functions, while non-essential applications may have less impact if disrupted.
C. Sensitivity of Data: Sensitive Data Handling: Classify applications based on the sensitivity of data they handle. Applications dealing with personally identifiable information (PII), financial data, or intellectual property may require heightened security measures.
D. User Access and Permissions: Privileged Access Applications: Identify applications that require elevated access levels or involve privileged operations. This classification helps manage user permissions and restrict access to sensitive functionalities.
E. Regulatory Compliance: Compliance-Critical Applications: Classify applications based on their relevance to regulatory compliance requirements. Certain applications may handle data subject to specific regulations, such as healthcare (HIPAA) or finance (PCI DSS).
F. Technology: Classifying applications based on their underlying technology stack, such as Java, .NET, or web applications.
G. Cloud-Native vs. Legacy: Cloud-Ready or Legacy: Differentiate between applications that are designed for cloud environments and those that may require modification or migration. This classification informs cloud adoption and modernization strategies.
H. Deployment Model: Classifying applications based on their deployment model, such as on-premises, cloud-based, or hybrid.
I. Lifecycle Stage: Development, Testing, Production: Classify applications based on their lifecycle stages. This helps manage development and testing environments separately from production and ensures appropriate controls at each stage.
J. Dependency Mapping: Interconnected Applications: Identify applications with dependencies on others. Understanding interconnections helps manage updates, maintenance, and potential impact on related systems.
K. Vendor Criticality: Vendor Dependency: Classify applications based on their reliance on specific vendors. Vendor criticality assessments inform risk management strategies, especially when dealing with third-party applications.
L. Access Channels: Web, Mobile, Desktop: Classify applications based on the channels through which users access them. This distinction helps tailor security measures for different access points.
M. Authentication Requirements: Authentication Intensity: Categorize applications based on the level of authentication required. High-security applications may demand multi-factor authentication, while others may rely on standard credentials.
N. Data Storage Locations: On-Premises, Cloud, Hybrid: Classify applications based on where they store data. Understanding data storage locations informs data residency considerations and compliance with data protection regulations.
O. Integration Complexity: Simple, Moderate, Complex: Assess the integration complexity of applications. This classification aids in prioritizing integration efforts and understanding potential challenges in interconnected systems.
P. User Impact upon Outage: High, Medium, Low Impact: Classify applications based on the potential impact on users in case of downtime. Critical applications with high impact may require more robust redundancy and disaster recovery measures.
Q. Security Posture: Secure, Needs Improvement: Evaluate the security posture of applications. This classification guides efforts to enhance security controls and address vulnerabilities.
iii. Benefits of Application Classification
A. Improved Application Portfolio Management: Classification provides a clear understanding of the application landscape, enabling better decision-making for rationalization, modernization, and resource allocation.
B. Enhanced Risk Management: Classification helps identify and prioritize security risks associated with different application types, enabling effective mitigation strategies.
C. Optimized IT Operations: Classification facilitates efficient resource allocation, cost optimization, and streamlined incident management.
D. Streamlined Compliance: Classification simplifies compliance audits and ensures adherence to industry standards and regulatory requirements.
E. Informed Decision-Making: Classification provides valuable insights for strategic planning, budgeting, and technology roadmap development.
The way an application is classified can affect various things such as its development process, how it is marketed, its user interface design, and how it integrates with other software.
Application classification is an essential practice for organizations that manage diverse application portfolios. It provides a structured approach to understanding, managing, and optimizing the application landscape, leading to improved IT governance, risk management, and cost efficiency.
Managing a crisis in a highly regulated industry presents unique challenges, and requires a calculated, swift, and compliant response, but it can be successfully navigated with a proactive and meticulous approach.
Effectively managing a crisis requires a comprehensive and well-coordinated approach that involves multiple stakeholders and a clear understanding of the regulatory landscape.
Here are some steps to consider:
A. Preparation and Prevention:
a. Establish a crisis management plan that outlines roles, responsibilities, communication protocols, and response procedures.
b. Conduct regular risk assessments to identify potential crisis scenarios and develop mitigation strategies.
c. Implement strong internal controls and risk management practices to prevent crises from occurring.
B. Understand Regulatory Obligations: Quickly assess and clearly understand the regulatory obligations that apply to the specific crisis situation. This includes legal requirements, reporting obligations, and any industry-specific regulations.
C. Early Detection and Response:
a. Establish clear channels for reporting and escalating potential crises.
b. Monitor industry news, social media, and internal sources for signs of emerging issues.
c. Respond promptly and decisively to crisis situations, taking initial steps to contain the situation and protect public safety.
D. Response Procedure: Establish a clear procedure about what steps to follow and who to notify during a crisis. It should assign responsibilities, provide guidance on decision-making regulations, and include steps for external and internal communication.
E. Stakeholder Engagement:
a. Engage with key stakeholders, including regulators, industry bodies, and community leaders, to seek support and cooperation.
b. Listen to concerns and feedback from stakeholders and incorporate their perspectives into the crisis response strategy.
c. Demonstrate a commitment to collaboration and transparency to build trust and maintain relationships.
F. Communication Strategy: Develop a comprehensive communication strategy that addresses both internal and external stakeholders. Clearly communicate the steps being taken to manage the crisis, comply with regulations, and ensure transparency.
G. Establish a Crisis Management Team:
a. A cross-functional team led by senior management that includes representatives from key departments, including legal, compliance, communications, operations, and senior leadership.
b. The team should be responsible for making swift decisions, coordinating responses, and communicating with stakeholders (including regulatory bodies).
H. Regulatory Compliance:
a. Thoroughly understand the applicable laws, regulations, and reporting requirements related to crisis management in your industry.
b. Work closely with regulatory agencies to ensure compliance with all requirements and maintain open communication channels.
c. Seek guidance from legal counsel to navigate complex regulatory issues and potential liability concerns.
I. Documented Evidence: Maintain well-documented evidence of every action taken during the crisis. This will not only aid in regulatory compliance but also provide valuable insights for future references.
J. Compliance with Reporting Requirements: Ensure timely and accurate reporting to relevant regulatory authorities as required by law. This may involve notifying regulatory bodies of incidents, providing updates, and collaborating transparently throughout the crisis.
K. Communication and Transparency:
a. Communicate openly and transparently with stakeholders, including customers, employees, partners, media, regulatory bodies and the public.
b. Provide accurate and timely information to address concerns and prevent misinformation from spreading.
c. Establish a designated spokesperson to represent the organization and convey its message consistently.
d. Use all available channels, such as press conferences, emails, social media, and your company’s website.
L. Liaise with Regulatory Bodies:
a. In a highly-regulated industry, cooperating fully with regulatory authorities to ensure that your crisis response is in compliance with the rules and regulations that govern your industry.
b. Designate a point of contact to liaise with regulatory authorities. This individual should be well-versed in regulatory requirements and be able to communicate effectively with regulators during the crisis.
c. Keep them informed, submit necessary reports, and follow given guidelines and procedures.
d. Cooperate with regulators; they are often perceived as adversaries, but in a crisis, they can offer valuable advice and support.
M. Legal Counsel: Engage legal counsel early in the crisis response to provide guidance on legal implications, regulatory compliance, and potential liabilities. Legal experts can help navigate complex regulatory landscapes.
N. Comprehensive Documentation and Record Keeping:
a. Maintain thorough records of all actions taken during the crisis along with their rationale.
b. This includes communication records, decision-making processes, and compliance efforts. Accurate records are essential for regulatory inquiries and investigations.
c. This can help manage legal and regulatory requirements, and provide valuable information for a post-crisis review.
O. Training and Preparedness:
a. Regularly train employees on crisis management procedures and ensure they are aware of their roles during a crisis.
b. Preparedness helps streamline the response and ensures a more effective compliance strategy.
P. Regulatory Updates:
a. Stay informed about any updates or changes in regulations related to the crisis.
b. Regulatory requirements may evolve, and staying current is crucial for maintaining compliance throughout the crisis management process.
Q. Internal Investigations: Conduct thorough internal investigations to determine the root cause of the crisis. This may involve collaboration between internal teams, external experts, and regulatory bodies, if necessary.
R. Engage External Experts: If the crisis requires specialized knowledge, consider engaging external experts or consultants who can provide insights into compliance issues, regulatory expectations, or specific industry challenges.
S. Collaborate with Industry Associations: Work collaboratively with industry associations to share best practices, insights, and lessons learned. Industry peers can offer valuable perspectives and support during challenging times.
T. Scenario Planning and Simulation: Conduct scenario planning and simulation exercises to prepare for potential crises. This helps identify gaps in the crisis response plan and ensures that teams are well-equipped to manage a crisis within regulatory constraints.
U. Recovery and Evaluation:
a. Post-crisis, conduct a thorough evaluation to analyze the effectiveness of the crisis management strategy.
b. This review provides valuable learnings and the opportunity to refine your plan, making it more robust for future scenarios.
c. Review to understand the root cause, learn lessons, identify improvements that can be made to prevent future occurrences, and update your crisis management plan accordingly.
d. Share learnings across the organization to enhance crisis preparedness and response capabilities.
V. Continuous Improvement: After the crisis is resolved, conduct a thorough debriefing to assess the response and identify areas for improvement. Use the lessons learned to enhance crisis management procedures and ensure ongoing compliance readiness.
Crisis management in highly regulated industries requires a proactive and comprehensive approach that emphasizes prevention, early detection, effective communication, compliance, and stakeholder engagement.
By implementing these key steps, organizations can effectively navigate crisis situations and minimize their impact on public safety, regulatory compliance, and brand reputation.
By combining regulatory expertise, effective communication, and a proactive approach, organizations in highly regulated industries can navigate crises while meeting compliance requirements and protecting their reputation.
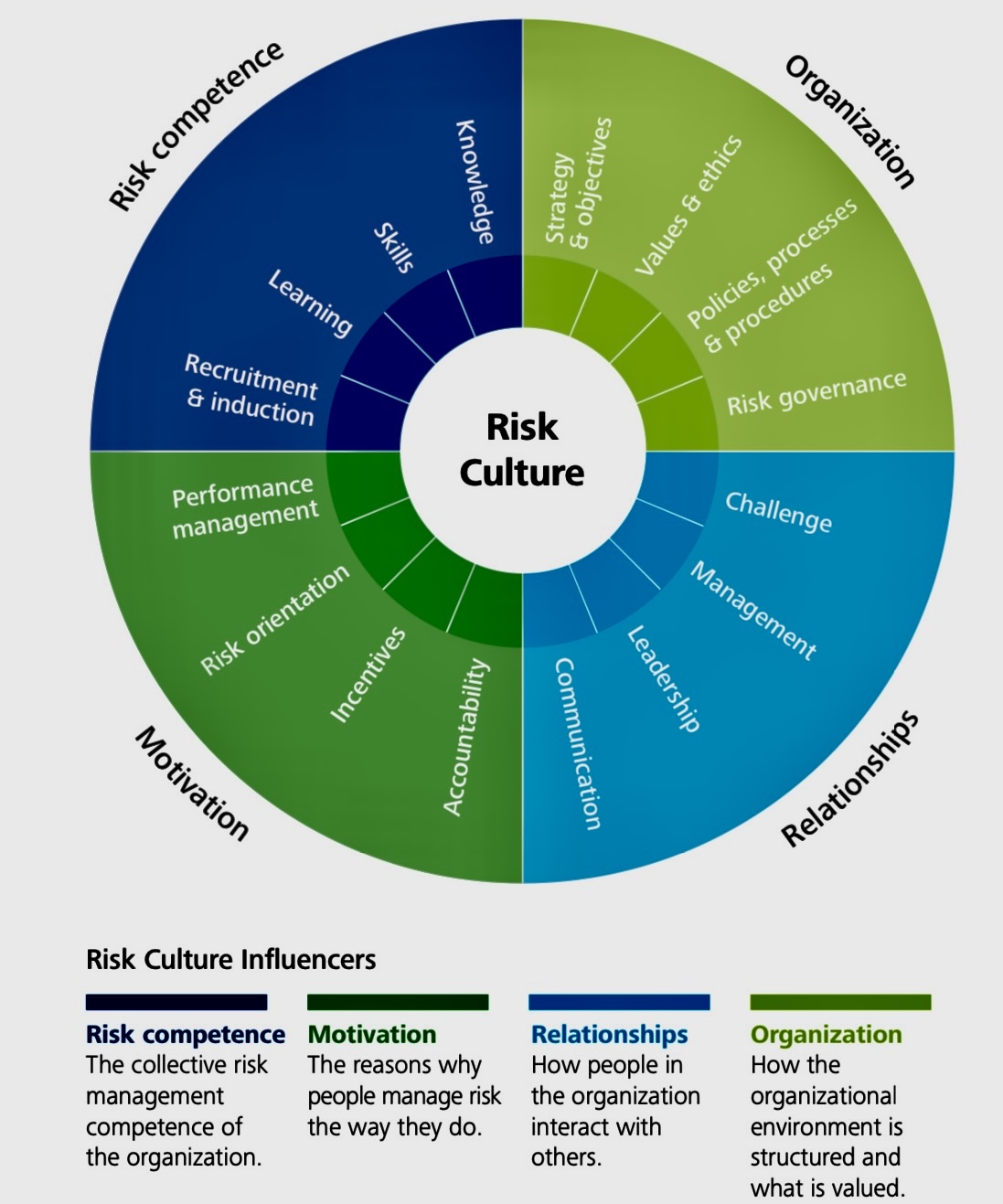
A risk culture, also known as a risk-aware culture, refers to the collective attitudes, values, beliefs, norms, and behaviors within an organization regarding risk management. It encompasses how employees and leaders perceive, approach, and deal with risks on a day-to-day basis. Prioritizing a strong risk culture is essential for several reasons:
A. Risk Awareness: A risk culture fosters awareness of potential risks and challenges within an organization. It encourages employees to recognize and report risks, whether they are related to financial, operational, compliance, or other aspects of the business.
B. Proactive Risk Management: A strong risk culture promotes proactive risk management, where employees take the initiative to identify and address risks before they escalate into major issues. This can lead to cost savings and a competitive advantage.
C. Risk Mitigation: Organizations with a risk-aware culture are better equipped to identify and implement strategies to mitigate risks effectively. This reduces the likelihood of major disruptions or losses.
D. Reduced Risks: When employees understand and manage risks, they can help prevent problems before they occur. They are more likely to recognize potential risks and take action to mitigate them.
E. Enhanced Decision-Making: In organizations with a strong risk culture, employees at all levels understand the types of risk that the organization is willing to accept. This can lead to better decision-making and risk-taking within the approved boundaries.
F. Adaptability: A risk culture encourages adaptability in the face of changing circumstances. When employees are comfortable with the idea of risk, they are more likely to adjust to new challenges and market conditions.
G. Compliance and Governance: A strong risk culture supports regulatory compliance and good governance practices, helping organizations avoid legal and ethical issues.
H. Regulatory Compliance: A strong risk culture helps to ensure compliance with regulations and standards, avoiding penalties and damage to the organization’s reputation.
I. Reputation and Trust: Organizations with a robust risk culture often enjoy a better reputation among clients, investors, and stakeholders. Trust is built through transparent and responsible risk management.
J. Increased Stakeholder Confidence: Stakeholders, including customers, employees, and investors, gain confidence in an organization that actively manages its risks.
K. Innovation: A balanced risk culture can also foster innovation. Employees who are encouraged to take calculated risks are more likely to propose new ideas and approaches, leading to growth and competitiveness.
L. Risk Communication: An organization with a risk culture is likely to have open and effective channels of risk communication. This ensures that relevant information about risks is shared throughout the organization, enabling better decision-making.
M. Business Resilience: Organizations with a strong risk culture are better equipped to bounce back from adversity because they have already thought through potential risks and have plans in place to mitigate them.
N. Competitive Advantage: Understanding and managing risks can enable an organization to seize opportunities that competitors may see as too risky.
O. Long-Term Success: Prioritizing a risk culture contributes to the long-term success of the organization. It helps prevent costly failures and setbacks, ultimately leading to sustainable growth and profitability.
There are a number of things that organizations can do to prioritize risk culture, including:
A. Get leadership buy-in: Senior management must be committed to risk culture and must set the tone for the organization.
B. Communicate and educate: Organizations must communicate the importance of risk culture to all employees and provide them with the training and resources they need to manage risks effectively.
C. Embed risk management into all processes: Risk management should be embedded into all organizational processes, from strategic planning to day-to-day operations.
D. Monitor and improve: Organizations should regularly monitor and improve their risk culture to ensure that it is effective and aligned with their needs.
Building a strong risk culture goes beyond just establishing policies or procedures; it’s about instilling values and attitudes that permeate the entire organization.
It encourages risk awareness, proactive risk management, adaptability, and ethical behavior, all of which contribute to a competitive advantage and long-term success. Prioritizing a risk culture is not just a matter of avoiding problems but of actively building a foundation for growth and resilience.
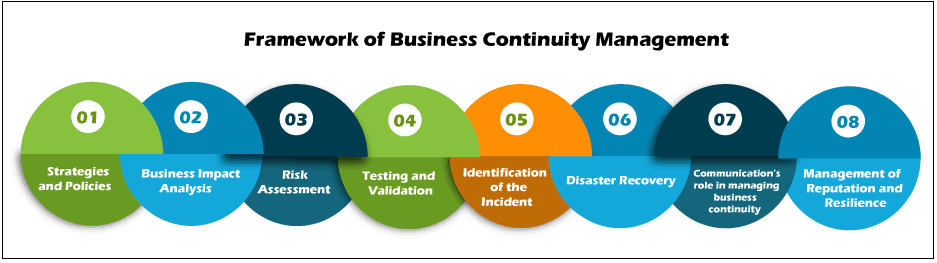
Auditing business continuity involves assessing an organization’s plans and strategies to keep its operations functional in the event of a disaster or any significant disruption.
Here are steps on how to audit business continuity:
A. Establish the Audit Scope: Determine what aspects of the organization’s continuity plan will be evaluated. This could include risk assessments, business impact analyses, recovery strategies and procedures, communication structures, or rehearsal and testing procedures.
B. Understand the Business Continuity Policy: Review the company’s policy on business continuity to understand what strategies and standards the organization has set. Understand the objectives of the business continuity plan.
C. Review the Business Continuity Plan (BCP): This plan should outline the organization’s strategy for maintaining operations during a disruption. The plan should have clear objectives, recovery strategies, and a comprehensive list of roles and responsibilities. Make sure it’s up to date and relevant to the organization needs.
D. Interview Key Personnel: Interview those involved in the creation and execution of the business continuity plan to understand their roles and responsibilities. This could include top management, department leaders, or designated crisis response team members.
E. Review Processes and Procedures: Examine the steps laid out for responding to a disruption. This can be anything from data backups, supply chain alternatives, customer communication procedures, to staff duties.
F. Check for Regulatory Compliance: Ensure that the business continuity plan adheres to all necessary laws and regulations specific to your industry.
G. Examine Risk Assessments: The organization should have conducted a risk assessment that identifies potential threats and vulnerabilities. Review this assessment to make sure all risks have been considered and that the BCP has strategies in place to mitigate those risks.
H. Business Impact Analysis (BIA): Evaluate the organization’s BIA, which should identify critical business functions and their dependencies. This analysis should also estimate the impact of these functions failing and the maximum acceptable outage time.
I. Check Training and Awareness Programs: Verify if the organization has training programs in place to educate employees about the BCP. Employees should be aware of their responsibilities during a disruption, and there should be regular drills to test the plan.
J. Evaluate Testing and Maintenance Procedures: Examine the process of testing the continuity plan and maintaining its relevance over time. This includes checking if regular tests are carried out, if there’s a procedure for updating the plan, and if lessons from any past disruptions were incorporated.
K. Evaluate Incident Management Plan: The plan should clearly outline the procedures to handle an incident, including communication strategies, escalation procedures, and recovery steps.
L. Test the Plan: The most effective way to evaluate a BCP is to conduct a mock disaster exercise. This will help identify any gaps or weaknesses in the plan. Make sure the organization conducts these exercises regularly and updates the BCP based on the results.
M. Investigate Resources and Tools: Take note of any resources or tools in place to support the continuity plan. This could include IT systems for data recovery, emergency supplies, or alternative work sites.
N. Assess Documentation: Check that all elements of the business continuity plan are properly documented and easily accessible by all relevant personnel.
O. Review Previous Audit Reports: If there have been previous audits of the BCP, review these reports for any unresolved issues that should be addressed.
P. Provide Recommendations: After identifying strengths and weaknesses of the plan, provide clear, actionable recommendations for improvement.
Q. Document and Report Findings: All findings from the audit should be documented and communicated back to the organization. This report should include any areas of non-compliance, risks identified, suggested improvements, and good practices observed.
Here are some additional considerations for auditing business continuity:
o Alignment with Business Objectives: Ensure the BCP aligns with the organization’s overall business objectives and risk tolerance levels.
o Regularity of Audits: Conduct regular audits to ensure the BCP remains current and effective in addressing evolving risks.
o Continuous Improvement: Encourage a culture of continuous improvement in business continuity planning and response capabilities.
o Management Commitment: Secure strong management commitment and support for business continuity initiatives.
o Training and Awareness: Provide regular training and awareness programs for employees on business continuity procedures and their roles in responding to disruptions.
The goal of auditing business continuity is not to point out failures or mistakes, but rather should aim to enhance the organization’s resilience and ensure they can weather any disruptions and recover effectively.