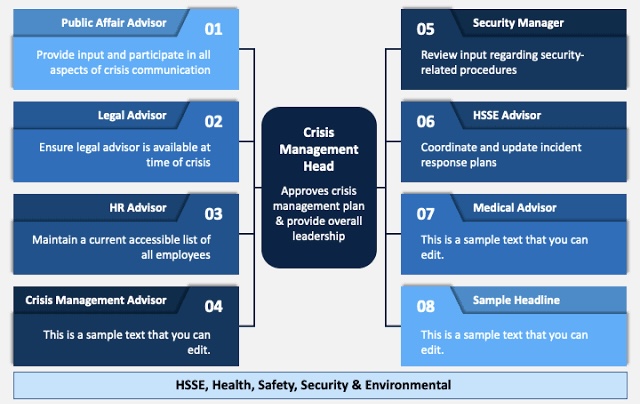
Understanding the CrowdStrike IT Outage: Insights from a Former Windows Developer
Introduction
Hey, I’m Dave. Welcome to my shop.
I’m Dave Plummer, a retired software engineer from Microsoft, going back to the MS-DOS and Windows 95 days. Thanks to my time as a Windows developer, today I’m going to explain what the CrowdStrike issue actually is, the key difference in kernel mode, and why these machines are bluescreening, as well as how to fix it if you come across one.
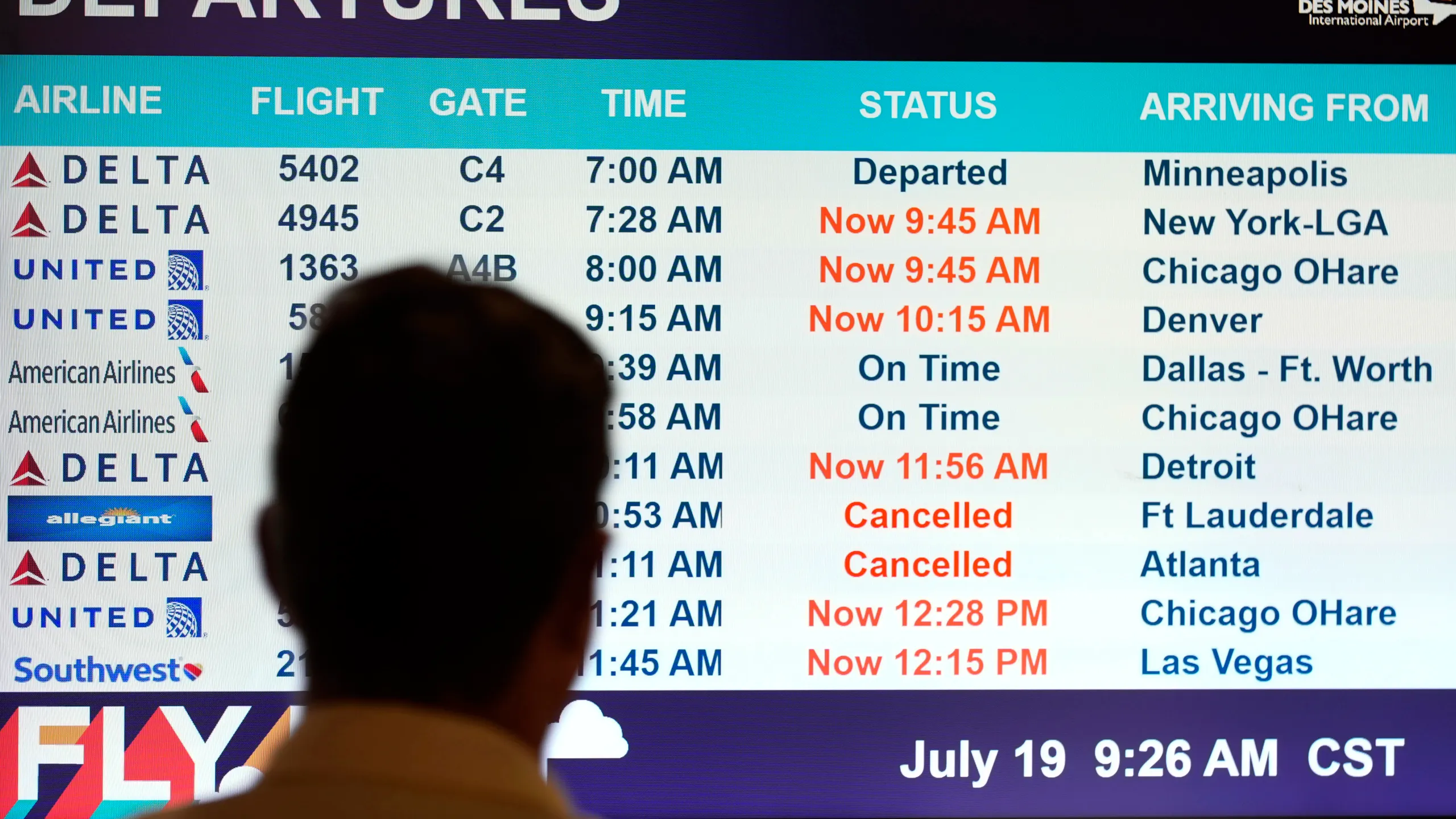
Now, I’ve got a lot of experience waking up to bluescreens and having them set the tempo of my day, but this Friday was a little different. However, first off, I’m retired now, so I don’t debug a lot of daily blue screens. And second, I was traveling in New York City, which left me temporarily stranded as the airlines sorted out the digital carnage.
But that downtime gave me plenty of time to pull out the old MacBook and figure out what was happening to all the Windows machines around the world. As far as we know, the CrowdStrike bluescreens that we have been seeing around the world for the last several days are the result of a bad update to the CrowdStrike software. But why? Today I want to help you understand three key things.
Key Points
- Why the CrowdStrike software is on the machines at all.
- What happens when a kernel driver like CrowdStrike fails.
- Precisely why the CrowdStrike code faults and brings the machines down, and how and why this update caused so much havoc.
Handling Crashes at Microsoft
As systems developers at Microsoft in the 1990s, handling crashes like this was part of our normal bread and butter. Every dev at Microsoft, at least in my area, had two machines. For example, when I started in Windows NT, I had a Gateway 486 DX 250 as my main dev machine, and then some old 386 box as the debug machine. Normally you would run your test or debug bits on the debug machine while connected to it as the debugger from your good machine.
Anti-Stress Process
On nights and weekends, however, we did something far more interesting. We ran a process called Anti-Stress. Anti-Stress was a bundle of tests that would automatically download to the test machines and run under the debugger. So every night, every test machine, along with all the machines in the various labs around campus, would run Anti-Stress and put it through the gauntlet.
The stress tests were normally written by our test engineers, who were software developers specially employed back in those days to find and catch bugs in the system. For example, they might write a test to simply allocate and use as many GDI brush handles as possible. If doing so causes the drawing subsystem to become unstable or causes some other program to crash, then it would be caught and stopped in the debugger immediately.
The following day, all of the crashes and assertions would be tabulated and assigned to an individual developer based on the area of code in which the problem occurred. As the developer responsible, you would then use something like Telnet to connect to the target machine, debug it, and sort it out.
Debugging in Assembly Language
All this debugging was done in assembly language, whether it was Alpha, MIPS, PowerPC, or x86, and with minimal symbol table information. So it’s not like we had Visual Studio connected. Still, it was enough information to sort out most crashes, find the code responsible, and either fix it or at least enter a bug to track it in our database.
Kernel Mode versus User Mode
The hardest issues to sort out were the ones that took place deep inside the operating system kernel, which executes at ring zero on the CPU. The operating system uses a ring system to bifurcate code into two distinct modes: kernel mode for the operating system itself and user mode, where your applications run. Kernel mode does tasks such as talking to the hardware and the devices, managing memory, scheduling threads, and all of the really core functionality that the operating system provides.
Application code never runs in kernel mode, and kernel code never runs in user mode. Kernel mode is more privileged, meaning it can see the entire system memory map and what’s in memory at any physical page. User mode only sees the memory map pages that the kernel wants you to see. So if you’re getting the sense that the kernel is very much in control, that’s an accurate picture.
Even if your application needs a service provided by the kernel, it won’t be allowed to just run down inside the kernel and execute it. Instead, your user thread will reach the kernel boundary and then raise an exception and wait. A kernel thread on the kernel side then looks at the specified arguments, fully validates everything, and then runs the required kernel code. When it’s done, the kernel thread returns the results to the user thread and lets it continue on its merry way.
Why Kernel Crashes Are Critical
There is one other substantive difference between kernel mode and user mode. When application code crashes, the application crashes. When kernel mode crashes, the system crashes. It crashes because it has to. Imagine a case where you had a really simple bug in the kernel that freed memory twice. When the kernel code detects that it’s about to free already freed memory, it can detect that this is a critical failure, and when it does, it blue screens the system, because the alternatives could be worse.
Consider a scenario where this double freed code is allowed to continue, maybe with an error message, maybe even allowing you to save your work. The problem is that things are so corrupted at this point that saving your work could do more damage, erasing or corrupting the file beyond repair. Worse, since it’s the kernel system that’s experiencing the issue, application programs are not protected from one another in the same way. The last thing you want is solitaire triggering a kernel bug that damages your git enlistment.
And that’s why when an unexpected condition occurs in the kernel, the system is just halted. This is not a Windows thing by any stretch. It is true for all modern operating systems like Linux and macOS as well. In fact, the biggest difference is the color of the screen when the system goes down. On Windows, it’s blue, but on Linux it’s black, and on macOS, it’s usually pink. But as on all systems, a kernel issue is a reboot at a minimum.
What Runs in Kernel Mode
Now that we know a bit about kernel mode versus user mode, let’s talk about what specifically runs in kernel mode. And the answer is very, very little. The only things that go in the kernel mode are things that have to, like the thread scheduler and the heap manager and functionality that must access the hardware, such as the device driver that talks to a GPU across the PCIe bus. And so the totality of what you run in kernel mode really comes down to the operating system itself and device drivers.
And that’s where CrowdStrike enters the picture with their Falcon sensor. Falcon is a security product, and while it’s not just simply an antivirus, it’s not that far off the mark to look at it as though it’s really anti-malware for the server. But rather than just looking for file definitions, it analyzes a wide range of application behavior so that it can try to proactively detect new attacks before they’re categorized and listed in a formal definition.
CrowdStrike Falcon Sensor
To be able to see that application behavior from a clear vantage point, that code needed to be down in the kernel. Without getting too far into the weeds of what CrowdStrike Falcon actually does, suffice it to say that it has to be in the kernel to do it. And so CrowdStrike wrote a device driver, even though there’s no hardware device that it’s really talking to. But by writing their code as a device driver, it lives down with the kernel in ring zero and has complete and unfettered access to the system, data structures, and the services that they believe it needs to do its job.
Everybody at Microsoft and probably at CrowdStrike is aware of the stakes when you run code in kernel mode, and that’s why Microsoft offers the WHQL certification, which stands for Windows Hardware Quality Labs. Drivers labeled as WHQL certified have been thoroughly tested by the vendor and then have passed the Windows Hardware Lab Kit testing on various platforms and configurations and are signed digitally by Microsoft as being compatible with the Windows operating system. By the time a driver makes it through the WHQL lab tests and certifications, you can be reasonably assured that the driver is robust and trustworthy. And when it’s determined to be so, Microsoft issues that digital certificate for that driver. As long as the driver itself never changes, the certificate remains valid.
CrowdStrike’s Agile Approach
But what if you’re CrowdStrike and you’re agile, ambitious, and aggressive, and you want to ensure that your customers get the latest protection as soon as new threats emerge? Every time something new pops up on the radar, you could make a new driver and put it through the Hardware Quality Labs, get it certified, signed, and release the updated driver. And for things like video cards, that’s a fine process. I don’t actually know what the WHQL turnaround time is like, whether that’s measured in days or weeks, but it’s not instant, and so you’d have a time window where a zero-day attack could propagate and spread simply because of the delay in getting an updated CrowdStrike driver built and signed.
Dynamic Definition Files
What CrowdStrike opted to do instead was to include definition files that are processed by the driver but not actually included with it. So when the CrowdStrike driver wakes up, it enumerates a folder on the machine looking for these dynamic definition files, and it does whatever it is that it needs to do with them. But you can already perhaps see the problem. Let’s speculate for a moment that the CrowdStrike dynamic definition files are not merely malware definitions but complete programs in their own right, written in a p-code that the driver can then execute.
In a very real sense, then the driver could take the update and actually execute the p-code within it in kernel mode, even though that update itself has never been signed. The driver becomes the engine that runs the code, and since the driver hasn’t changed, the cert is still valid for the driver. But the update changes the way the driver operates by virtue of the p-code that’s contained in the definitions, and what you’ve got then is unsigned code of unknown provenance running in full kernel mode.
All it would take is a single little bug like a null pointer reference, and the entire temple would be torn down around us. Put more simply, while we don’t yet know the precise cause of the bug, executing untrusted p-code in the kernel is risky business at best and could be asking for trouble.

Post-Mortem Debugging
We can get a better sense of what went wrong by doing a little post-mortem debugging of our own. First, we need to access a crash dump report, the kind you’re used to getting in the good old NT days but are now hidden behind the happy face blue screen. Depending on how your system is configured, though, you can still get the crash dump info. And so there was no real shortage of dumps around to look at. Here’s an example from Twitter, so let’s take a look. About a third of the way down, you can see the offending instruction that caused the crash.
It’s an attempt to move data to register nine by loading it from a memory pointer in register eight. Couldn’t be simpler. The only problem is that the pointer in register eight is garbage. It’s not a memory address at all but a small integer of nine c hex, which is likely the offset of the field that they’re actually interested in within the data structure. But they almost certainly started with a null pointer, then added nine c to it, and then just dereferenced it.
CrowdStrike driver woes
Now, debugging something like this is often an incremental process where you wind up establishing, “Okay, so this bad thing happened, but what happened upstream beforehand to cause the bad thing?” And in this case, it appears that the cause is the dynamic data file downloaded as a sys file. Instead of containing p-code or a malware definition or whatever was supposed to be in the file, it was all just zeros.
We don’t know yet how or why this happened, as CrowdStrike hasn’t publicly released that information yet. What we do know to an almost certainty at this point, however, is that the CrowdStrike driver that processes and handles these updates is not very resilient and appears to have inadequate error checking and parameter validation.
Parameter validation means checking to ensure that the data and arguments being passed to a function, and in particular to a kernel function, are valid and good. If they’re not, it should fail the function call, not cause the entire system to crash. But in the CrowdStrike case, they’ve got a bug they don’t protect against, and because their code lives in ring zero with the kernel, a bug in CrowdStrike will necessarily bug check the entire machine and deposit you into the very dreaded recovery bluescreen.
Windows Resilience
Even though this isn’t a Windows issue or a fault with Windows itself, many people have asked me why Windows itself isn’t just more resilient to this type of issue. For example, if a driver fails during boot, why not try to boot next time without it and see if that helps?
And Windows, in fact, does offer a number of facilities like that, going back as far as booting NT with the last known good registry hive. But there’s a catch, and that catch is that CrowdStrike marked their driver as what’s known as a bootstart driver. A bootstart driver is a device driver that must be installed to start the Windows operating system.
Most bootstart drivers are included in driver packages that are in the box with Windows, and Windows automatically installs these bootstart drivers during their first boot of the system. My guess is that CrowdStrike decided they didn’t want you booting at all without their protection provided by their system, but when it crashes, as it does now, your system is completely borked.

Fixing the Issue
Fixing a machine with this issue is fortunately not a great deal of work, but it does require physical access to the machine. To fix a machine that’s crashed due to this issue, you need to boot it into safe mode, because safe mode only loads a limited set of drivers and mercifully can still contend without this boot driver.
You’ll still be able to get into at least a limited system. Then, to fix the machine, use the console or the file manager and go to the path window like windows, and then system32/drivers/crowdstrike. In that folder, find the file matching the pattern c and then a bunch of zeros 291 sys and delete that file or anything that’s got the 291 in it with a bunch of zeros. When you reboot, your system should come up completely normal and operational.
The absence of the update file fixes the issue and does not cause any additional ones. It’s a fair bet that the update 291 won’t ever be needed or used again, so you’re fine to nuke it.